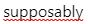For those of you that have seen Social Dilemma, you know we live in a world that is largely curated by algorithms that are constantly assessing our likes and interests. Social media has developed into an engagement machine. The side effect of such a thing is that the algorithms will start to hide things your friends post on Facebook without you doing anything. Some of you are perpetually hidden from me and I am likely perpetually hidden from some of you. So when I share something, only the people that interact with me constantly see it.
Recently I posted that journalists may be reporting black people’s stories wrong. It was an easy dig at the inadequate reporting done on the Testifying While Black study. When you look at the big picture, journalism sucks right now, and right now is when we need to get the word out that stenographic court reporters are needed. If there was another way to get their attention, I’d take it, but I’ve been playing diplomat for two years, and we are running out of time. Perfect example? Last year I agreed to speak with Frank Runyeon. I said if he’d ever like to write anything on court reporting, he could consider me a resource. Sure, he said, just write him in 6 to 8 months. When I did, he didn’t bother to respond. I’m pretty sure there was an Alice Cooper song for this.
Our shortage is mathematically simple. Years ago I had the privilege of hearing Mirabai Knight speak about it and I completely agreed with her. There are a limited number of people that will be good at steno and want to do stenography for a living. We can’t really affect that number much. What we can impact heavily is the number of people that hear about stenography. That’s one of the reasons Open Steno was born. That’s one of the reasons this blog was born. We can no longer sit back and trust that it’ll all work out. The people that want to replace you with inadequate technology aren’t leaving this up to chance. Any time they can put their thumb on the scale, they do, and when they lose, they whine loudly.
So, without reservation, I choose to put my thumb on the scale and occasionally use the same tools weaponized against us. If clickbait journalism is the way of the future, then let it work for us. I set up an ad campaign to get my article in front of journalists and bloggers, but like I said on my Facebook page, when the money’s dried up, that’s the end of that.
Just don’t tell my girlfriend what I spent our vacation money on.
If you’d like to join me on this, I’d ask you to head over to social media and share my Facebook post, the Stenonymous post, or the original blog post with the hashtags #journalism and #clickbaitJournalism. You can share as is, say something horrible about it, or say something nice. If you feel comfortable doing so, please set the privacy settings to public on the post where you share it. When the ad money’s gone, the hashtags will live on. There’s evidence that failing to utilize stenographers will adversely impact people that don’t speak a certain way. This one’s for them.
Very often on stenographer social media, we get questions about whether something should be reflected as said, sic’d, or “corrected.” There has been plenty of discussion over the years on whether to correct lawyers’ or witnesses’ speaking in transcription. There are a lot of ways to take this conversation, and in the spirit of keeping this fun, I’ll hit the highlights.
Necessary in this discussion is: “What is my transcript?” The bulk of freelance work goes to deposition reporting. When a case is filed and initial motions to dismiss are decided, if the case is not dismissed, it moves to discovery. Discovery is where the parties exchange information that they have so that when it is time for trial, there are few or no “surprise” pieces of evidence. At the conclusion of discovery, the parties can ask the court to decide the case as a matter of law if there are no factual questions in dispute. If the case cannot be resolved as a matter of law, it goes on to trial. An integral part of the discovery phase is deposition testimony. Parties have an opportunity to question the other side’s witnesses under oath. Witness testimony is evidence, and the evidence unveiled during the discovery phase is ultimately what helps parties settle cases, courts decide whether a matter can be decided as a matter of law, impeach witnesses at trial, and appellate courts review the decisions of the trial court. In America, the testimony of one witness can convict beyond a reasonable doubt. Your transcript is the verbatim record of what occurred during the testimony, and again, that testimony is powerful evidence.
Unsurprisingly, there are many different takes on what “verbatim” means. We can all read the dictionary definition: “in exactly the same words that were used originally.” But court reporting and transcription are service industries, and there have been many times where court reporters are pressured by a client or company to change that verbatim record in some small way. In my view, that pressure gave life to a lot of court reporter conventions that are daunting for students, new reporters, and even veteran reporters to master. For example, as a young reporter, I was told to take out false starts, never ever report “um,” and to even physically remove strikes and withdrawns from deposition transcripts. Now, wherever you are, the laws in your jurisdiction supersede my advice or opinion, but I am going to share the way I look at each in the hopes that this can be shared with others who struggle with these. For sure, anything I write can and will be debated, but debate can only improve our field.
Removing False Starts
This was drilled into me by agencies as a young reporter. “Always remove false starts.” It’s still being pushed on young reporters today, to the point where some may not even be taking them down. Frankly, I see this as bad advice. The essential factors for a reporter to consider in the way something is transcribed are context and readability. Does my transcription of the verbatim notes change the context of this testimony? Does my transcription degrade the readability of this testimony? In my view, removing most false starts will not actually change context, and they will improve readability. As an example:
“Q. Are you — did you go to the store?”
“A. Yes.”
It would be difficult to argue that removing the words “are you” and simply changing the question to “Did you go to the store?” hurts the context. Nothing has changed. And so to the extent removing false starts is looked at favorably in our field, I get it. But what about when it would change context?
“Q. Are you — I mean, did you go — did you go to the — sorry. Did you, if you remember, go to the store?”
“A. I’m sorry. I don’t understand your question.”
What happens in a world where a young reporter, told that they must remove false starts, removes all that and changes it to “Did you, if you remember, go to the store?” The context is unequivocally changed. Verbatim, it’s very clear that the question was not clear. There was a lot of extra “stuff” in there. If such a question is cleaned up, it makes the witness look like they’re not paying attention or unintelligent. Removing false starts can hurt the context and stop legal professionals from doing their job. Imagine that the deposition is taken by a young associate and the trial lawyer is a seasoned vet who did not sit on the deposition. Reading a “cleaned up” version, the trial lawyer might believe the witness is a bumbling mess. When that witness gets on the stand and is given clear questions, it’s going to be a surprise for that trial lawyer. So even where law may allow the removal of false starts, it’s a decision the court reporting practitioner should make using their own sound judgment, and not on the whims of an agency or client. You may also want to see NCRA Advisory Opinion 4 to the extent it touches on this topic.
Never Ever Report Um
Again, I see the reporting of “um” as a matter of context and readability. Let’s say that you’re taking a motion argument, and it looks something like:
“MS. ATTORNEY: Um, um, um, um, um, um, um, um, um — your Honor, based on the hearing that we just had, there is no set of facts under which the people may prevail. I therefore ask you to dismiss this case in the interest of justice.”
Does it really change anything if you don’t report the ums in that specific instance? Nope. And this isn’t a hypothetical. I recall a situation just like this, where the attorney had, without question, made the point they were trying to make, and then became very flustered asking the court to make a decision. But what if the situation was a trial situation?
“Q. Did you see Mr. Vanhorten shoot Mr. Gorfasi?”
“A. Um, well — um, yes.”
If you transcribe that sentence as “well, yes” the context is destroyed. The witness seems crystal clear on what they saw. Those ums have a kiloton of context that transform what is being said. I’m not here to say anyone who omits an um is a bad reporter, but think twice before subscribing blindly to the “truism” that we do not report ums.
Physically Remove Strike That or Withdrawn
Often, strike that is seen as a false start. Just imagine the typical scenario:
“Q. Were you — strike that. Were you ever an employee of ABC Corporation?”
Again, the rule of context comes into play. In the above scenario, I can’t say I see a big problem with the omission of the false start strike that. But as a mentor to many over the years, I’ve come across the following scenario:
“Q. Were you ever an employee of ABC Corporation?”
“A. Well, I wasn’t an employee at the time.”
“MR. GUY: Move to strike.”
What have mentees come back and said? “Chris, my agency says remove strikes. Do I remove that whole thing?” Working reporters have had to counsel many a new reporter. “No. We cannot remove portions. That motion to strike is the attorney preserving their motion on the record, which will be later reviewed by a court.”
Ultimately, with these three categories, leaving things in as they are said is often the way to go. A court can always seal, strike, or disregard something that shouldn’t be in the transcript. On the other hand, a reporter that does not put something in the transcript can be questioned about why it was removed, or even have their neutrality called into question.
Mispronunciations
Now that we’ve explored some of the common things that impact context, let’s explore some more “what ifs.” Since I was a newbie, the discussion has come up, “Someone said a word incorrectly. Should I sic this?” This comes from a very literal way of thinking sometimes cleverly but pejoratively termed in our field as “the literati.” The pressure is turned up to make something “perfectly verbatim” when there is a video, which brings up the question “are we not being verbatim when the video camera’s not on?” There are two major schools of thought, literal verbatim and readability, and within those schools of thought, you have many different situations and many different gradients. I could not possibly address each one, but let’s hit some common examples.
“Let me ax you a question.” It’s obvious to anyone that the speaker means to say ask. Many speakers do not enunciate clearly. It does not change the context to transcribe “ask,” and it greatly improves the readability, so for such moments where the context is not endangered and the word is obvious, there’s no harm in having the correct word rather than some kind of phonetic spelling. I would say the same for names. Let’s say someone’s name is Dr. Giglio. One person says “Jig-lee-oh” and the other says “Gig-lee-oh.” Again, if it’s clear that this is the same person, and the context is not endangered, transcribing the correct name is the way to go. If it’s not clear, then it’s time to speak up and get some clarification on the spelling! This is not to say you can never write a name phonetically, but try to make these spellings consistent throughout the transcript to the extent people are saying the same word, even if they say it a little differently.
“It’s supposably true.” In addition to not changing context by being too verbatim, we have to be mindful that sometimes people use words that sound like other words. If someone says a “wrong” word or a word we are not accustomed to hearing, we must resist the urge to correct, because that actually can alter context. We must also take the time to research things we are not a hundred percent sure on. In my book, supposably was not a word. The WordPress spellchecker says it’s not a word. I came to learn, a decade into my career, that supposably means “as may be conceived or imagined.” Supposedly is more of a synonym for allegedly. Was this true 10 years ago? I have no idea. As court reporters, we face the harsh reality of language drift. Words fall in and out of use. People do not speak as we were taught. So while you might correct something like axing a question, you have to think twice before you correct something that’s “supposably wrong.” If you have three minutes, check out my favorite video illustrating language drift. You can go back about 700 years before English starts sounding like gibberish and giraffes were camelopards. Through a mix of self-initiated research and our continuing education culture, we keep ourselves ahead of the average transcriber.
Whether there is video or not, you want a clear and logical reason why you have transcribed something the way you transcribed it. In my view, the strongest reason for a transcription choice is “transcribing it any other way would change the context or was not verbatim.” Reporter convention and training take a backseat to that.
What devilry is this?
Dialects
Court reporters are masters of English dialects even when we have no training. There is a study out there that pretty much shows we are twice as accurate as laypeople when transcribing the AAVE dialect. The thing that makes us, as humans, so much better than computers at transcribing speech that has a dialect or an accent is our ability to understand context. For example, in the Northern Cities Vowel Shift dialect, someone might say something that sounds like “she went down the black.” Dependent upon the context, we know that that sentence can be “she went down the block.” In brief, our ability to look at the totality of a statement is important. What a reporter may hear is “down the black.” But what must be transcribed, in the interest of both context and readability, is “down the block,” unless there’s some context that tells us “black” is actually correct.
This is also where our ability to speak up for the record comes into play, because if a reporter is unsure, they can seek clarification. For purposes of our work, dialects and accents are very much like garden-path sentences where a sentence goes in a different direction from what you were anticipating; we can discern what’s said from the context. Though accents are a different animal from dialects, the same rules apply. Early in my career, I had a gentleman say something that sounded like “I got up and leave her.” Through context I knew the statement was “I gotta pull a lever.” He was explaining how to open bus doors! Another man talked about the “zeh bruh lies or stripes” on the road, which could only be “zebra lines or stripes.” We’re not here to pick apart how something was said, we’re here to take down what was said.
Latin
“Vice-a versa” versus “vice versa.” “Neezy preezy” versus “nisi prius.” “Nun pro tunc” versus “nunc pro tunc.” “In forma papyrus” versus “in forma pauperis.” Because of Latin’s considerable history and various modern regional pronunciation schemes, this is another thing that gets confusing fast. My advice? Treat it like mispronunciations. Treat it like dialects. Treat it like all these other examples and look at the context. If someone says, objectively, the wrong phrase, then don’t change it for them, but if you know exactly what they said, don’t transcribe it phonetically for the sake of “verbatim.” Take a look.
“MR. GUY: Quid pro quo is the Latin phrase for ‘from possibility to actuality.'”
So we head over to Google, and we can see clearly that “a posse ad esse” is the Latin phrase for that. Quid pro quo means “something for something.” No correction is necessary here. We knew what was meant, but the wrong thing was said. Verbatim is our friend. But what if it’s just a butchered pronunciation?
“MR. GUY: vee-low-shee-yee-yus quam asparagi coke-a-tor is the Latin phrase for ‘faster that asparagus can be cooked.'”
MR. GUY: velocius quam asparagi coquantur is the Latin phrase for ‘faster than asparagus can be cooked.'”
If you’re following along, you can probably tell that I think the second one is the obvious choice. No matter how butchered that pronunciation might be, if it’s clear, transcribing the wrong word or a series of phonetic jabs is what a computer would do. You’re better than that, use it to your advantage. And do not be too hard on yourself for making a mistake. I have had colleagues that were told the incorrect spelling of Latin phrases by people far more educated than many of us are. Whatever the issue, learn from various mistakes and situations, try not to become so rigid with regard to language that it endangers context, and continue to grow.
But I Was Taught This Way
Whenever stuff like this comes up, inevitably you’ll get responses like “but I was taught this way,” or “I’ve been doing it my way for 30 years.” Nobody can really fight with that. We have to respect one another and those various perspectives, backgrounds, and experiences. But I’ve come to look at it from a liability and reputation perspective for the freelance court reporter. If someone questioned you on a transcript, how would you respond? “My agency told me to” is a very unsafe response, because the agency can just say they didn’t, and if you’re an independent contractor, they’re not supposed to have direction and control over you. So take a look at the practice, and imagine being questioned on it. “That’s what you said” is a much stronger response than “everybody does it this way.”
We have to deal with the fact that, while we may live in a world of “truisms,” like “clients expect us to clean up the record,” these things are not universal, and in fact, as a young reporter, I had a lawyer tell me “you can’t change [false starts], it’s part of the record!” Imagine being about 20, and repeatedly told that “everyone cleans it up,” “this is normal,” “this is expected,” “you’re a bad reporter if you don’t fix it,” and then being slammed with “you can’t take that out.” It’s not surprising to me that there are reporters of all ages and experience levels that struggle with this. I’m really hoping this helps the strugglers: I was you. You’re not going to have an immediate answer for every situation, but having an objective or neutral method for how you make these decisions is imperative. If problems arise, and they occasionally do, you’re going to be defending your work. Remember, this is all about having an accurate record for review by the parties, trial courts, and appellate courts. Our expertise is what stops errors like “lawyer dog” from making it into the record and ruining people’s lives. If your work hasn’t changed the context of a statement and the transcript is readable, you’re off to a great start.
There’s a lot of conjecture when it comes to automatic speech recognition (ASR) and its ability to replace the stenographic reporter or captioner. You may also see ASR referred to as NLP or natural language processing. An important piece of the puzzle is understanding the basics behind artificial intelligence and how complex problems are solved. This can be confusing for reporters because in any of the literature on the topic, there are words and concepts that we simply have a weak grasp on. I’m going to tackle some of that today. In brief, computer programmers are problem solvers. They utilize datasets and algorithms to solve problems.
What is an algorithm?
An algorithm is a set of instructions that tell a computer what to do. You can also think of it as computer code for this discussion. To keep things simple, computers must have things broken down logically for them. Think of it like a recipe. For example, let’s look at a very simple algorithm written in the Python 3 language:
Do not despair. I’m about to make this so easy for you.
Line one tells the computer to put the words “The stenographer is _.” on the screen. Line two creates something called a Stenographer, and the Stenographer is equal to whatever you type in. If you input the word awesome with a lowercase or uppercase “a” the computer will tell you that you are right. If you input anything else, it will tell you the correct answer was awesome. Again, think of an algorithm like a recipe. The computer is told what to do with the information or ingredients it is given.
What is a dataset?
A dataset is a collection of information. In the context of machine learning, it is a collection that is put into the computer. An algorithm then tells the computer what to do with that information. Datasets will look very different dependent on the problem that a computer programmer is trying to solve. As an example, for enhancing facial recognition, datasets may be comprised of pictures. A dataset may be a wide range of photos labeled “face” or “not face.” The algorithm might tell the computer to compare millions of pictures. After doing that, the computer has a much better idea of what faces “look like.”
What is machine learning?
As demonstrated above, algorithms can be very simple steps that a computer goes through. Algorithms can also be incredibly complex math equations that help a computer analyze datasets and decide what to do with similar data in the future. One issue that comes up with any complex problem is that no dataset is perfect. For example, with regard to facial recognition, there have been situations with almost 100 percent accuracy with lighter male faces and only 80 percent accuracy with darker female faces. There are two major ways this can happen. One, the algorithm may not accurately instruct the computer on how to handle the differences between a “lighter male” face and a “darker female” face. Two, the dataset may not equally represent all faces. If the dataset has more “lighter male” faces in this example, then the computer will get more practice identifying those faces, and will not be as good at identifying other faces, even if the algorithm is perfect.
Artificial intelligence / AI / voice recognition, for purposes of this discussion, are all synonymous with each other and with machine learning. The computer is not making decisions for itself, like you see in the movies, it is being fed lots of data and using that to make future decisions.
Why Voice Recognition Isn’t Perfect and May Never Be
Computers “hear” sound by taking the air pressure from a noise into a microphone and converting that to electronic signals or instructions so that it can be played back through a speaker. A dataset for audio recognition might look something like a clip of someone speaking paired with the words that are spoken. There are many factors that complicate this. Datasets might be focused on speakers that speak in a grammatically correct fashion. Datasets might focus on a specific demographic. Datasets might focus on a specific topic. Datasets might focus on audio that does not have background noises. Creating a dataset that accurately reflects every type of speaker in every environment, and an algorithm that tells the computer what to do with it, is very hard. “Training” the computer on imperfect datasets can result in a word error rate of up to 75 percent.
This technology is not new. There is a patent from 2000 that seems to be a design for audio and stenographic transcription to be fed to a “data center.” That patent was assigned to Nuance Communications, the owner of Dragon, in 2009. From the documents, as I interpret them, it was thought that 20 to 30 hours of training could result in 92 percent accuracy. One thing is clear: as far back as 2000, 92 percent accuracy was in the realm of possibility. As recently as April 2020, the data studied from Apple, IBM, Google, Amazon, and Microsoft was 65 to 80 percent accuracy. Assuming, from Microsoft’s intention to purchase Nuance for $20 billion, that Nuance is the best voice recognition on the market today, there’s still zero reason to believe that Nuance’s technology is comparable to court reporter accuracy. Nuance Communications was founded in 1992. Verbit was founded in 2016. If the new kid on the block seriously believes it has a chance of competing, and it seems to, that’s a pretty good indicator that Nuance’s lead is tenuous, if it exists at all. There’s a list of problems for automation of speech recognition, and even though computer programmers are brilliant people, there’s no guarantee any of them will be “perfectly solved.” Dragon trains to a person’s voice to get its high level of accuracy. It simply would not make economic sense to have hours of training a software to everyone who is going to speak in court forever until the end of time, and the process would be susceptible to sabotage or mistake if it was unmonitored and/or self-guided (AKA cheap).
This is all why legal reporting needs the human element. We are able to understand context and make decisions even when we have no prior experience with a situation. Think of all the times you’ve heard a qualified stenographer, videographer, or voice writer say “in 30 years, I’ve neverseen that.” For us, it’s just something that happens, and we handle whatever the situation is. For a computer that has never been trained with the right dataset, it’s catastrophic. It’s easy, now, to see why even AI proponents like Tom Livne have said that they will not remove the human element.
Why Learning About Machine Learning Is Important For Court Reporters
Machine learning, or applications fueled by machine learning, are very likely to become part of our stenographic software. If you don’t believe me, just read this snippet about Advantage Software’s Eclipse AI Boost.
Don’t get out the pitchforks. Just consider what I have to blog.
If you’ve been following along, you’ve probably figured out, and it pretty much lays it out here, that datasets are needed to train “AI.” There are a few somewhat technical questions that stenographic reporters will probably want answered at some point:
Is this technology really sending your audio up to the Cloud and Google?
Is Google’s transcription reliable?
How securely is the information being sent?
Is the reporter’s transcription also being sent up to the Cloud and Google?
The reasons for answering?
The sensitive nature of some of our work may make it unsuitable for being uploaded. To the extent stuff may be confidential, privileged, or ex parte, court reporters and their clients may simply not want the audio to go anywhere.
Again, as shown in “Racial disparities in automated speech recognition” by Allison Koenecke, et al., Google’s ASR word error rate can be as high as 30 percent. Having to fix 30 percent of a job is a frightening possibility that could be more a hindrance than a help. I’m a pretty average reporter, and if I don’t do any defining on a job, I only have to fix 2 to 10 percent of any given job.
If we assume that everyone is fine with the audio being sent to the cloud, we must still question the security of the information. I assume that the best encryption possible would be in use, so this would be a minor issue.
The reporter’s transcription carries not only all the same confidential information discussed in point 1, but also would provide helpful data to make the AI better. Reporters will have to decide whether they want to help improve this technology for free. If the reporter’s transcription is not sent up with the audio, then the audio would only ostensibly be useful if human transcribers went through the audio, similar to what Facebook was caught doing two years ago. Do we want outside transcribers having access to this data?
Our technological competence changes how well we serve our clients. Nobody reading this needs to become a computer genius, but being generally aware of how these things work and some of the material out there can only benefit reporters. In one of my first posts about AI, I alluded to the fact that just because a problem is solvable does not mean it will be solved. I didn’t have any of the data I have today to assure me that my guess was correct. But I saw how tech news was demoralizing my fellow stenographers, and I called it as I saw it even though I risked looking like an idiot.
It’s my hope that reporters can similarly let go of fear and start to pick apart the truth about what’s being sold to them. Talk to each other about this stuff, pros and cons. My personal view, at this point, is that a lot of these salespeople saw a field with a large percentage of women sitting on a nice chunk of the “$30 billion” transcription industry, and assumed we’d all be too risk averse to speak out on it. Obviously, I’m not a woman, but it makes a lot of sense. Pick on the people that won’t fight back. Pick on the people that will freeze their rates for 20 or 30 years. Keep telling a lie and it will become the truth because people expect it to become the truth. Look how many reporters believe audio recording is cheaper even when that’s not necessarily true.
Here’s my assumption: a little bit of hope and we’ve won. Decades ago, a scientist named Richter did an experiment where rats were placed in the water. It took them a few minutes to drown. Another group of rats were taken out of the water just before they drowned. The next time they were submerged, they swam for hours to survive. We’re not rats, we’re reporters, but I’ve watched this work for humans too. Years ago, doctors estimated a family member would live about six more months. We all rallied around her and said “maybe they’re wrong.” She went another three years. We have a totally different situation here. We know they’re wrong. Every reporter has a choice: sit on the sideline and let other people decide what happens or become advocates for the consumers we’ve been protecting for the last 140 years, before the stenotype design we use today was even invented. People have been telling stenographers that their technology is outdated since before I was born, and it’s only gotten more advanced since that time. Next time somebody makes such a claim, it’s not unreasonable for you to question it, learn what you can, and let your clients know what kind of deal they’re getting with the “new tech.”
Addendum 4/27/21:
Some readers checked in with the Eclipse AI Boost, and as it was relayed to me, the agreement is that Google will not save the audio and will not be taking the stenographic transcriptions. Assuming that this is true, my current understanding of the tech is that stenographers would not be helping improve the technology by utilizing this technology unless there’s some clever wordplay going on, “we’re not saving the audio, we’re just analyzing it.” At this point, I have no reason to suspect that kind of a game. In my view, our software manufacturers tend to be honest because there’s simply no truth worth getting caught in a lie over. The worst I have seen are companies using buzzwords to try to appease everyone, and I have not seen that from Advantage.
Admittedly, I did not reach out to Advantage myself because this was meant to assist reporters with understanding the concepts as opposed to a news story. But I’m very happy people took that to heart and started asking questions.
About four months ago, I sat down with Alzo Slade and talked with VICE about the study that showed court reporters had only 80 percent accuracy when taking down African American English dialect (AAE). It aired 6/18/20. There’s a Youtube mirror. This study was a shocker for many because people look at our general accuracy of 95 percent, and then they look to a number like 80 percent, and it worries them. It worried me at the time, and I continued to cover it on this blog as more information came out. I was at VICE HQ Brooklyn for two hours, but only a few seconds made it into the segment, so please be understanding when it comes to what “made the cut.”
I was identified as a stenographic reporter with a lot of knowledge about the study. We all have a choice to make when approached by the press or any individual. Stonewall or try to present the facts? I chose the latter this time. A few things I would love to see more widely talked about:
AAE is not spoken by all black people. It’s a specific English dialect. I learned it also has rules and structure. It’s not “slang.”
Despite most of us having no formal training, we get it right about twice as often as the average person and 1.5 more often than the average lawyer, if you look at the pilot studies. There’s also no good alternative. AI does worse on all speakers and even worse than that on AAE. We’re talking as low as 20 percent accuracy.
In actual court cases we have some context. We don’t just take down random lines. This doesn’t prevent all errors, but it helps court reporters a lot.
We don’t interpret. People concerned with our interpretations don’t always realize that. Interpreting only matters in terms of correctly interpreting what we’ve heard. Interpretation of jurors and lawyers matters much more, which is why it’s so important for us to get the words correctly for them. We can educate people on this topic and help them understand big time.
This issue is not necessarily a racial or racist one. Mr. Slade himself read the AAE sentence on paper during the segment “She don’t stay, been talking about when he done got it.” His response was something like “what the hell is this?” Anybody can have trouble with a new dialect. I know I have heard some AAE statements and done very well, and heard other AAE statements and done poorly. I’m big on the opinion that exposure is the only way to get better.
Studies like this only highlight the need for stenographic court reporters that truly care about the record. If you meet a young person interested in courtroom equality, it might be worth having the “become a court reporter” talk. We care, and we want every single person that fills our shortage to care too.
One thing I learned from this media appearance is always keep your cool. At one point during my two hours there I felt very defensive and even a little worried they’d edit the segment in a way that was not fair to me. I kept my cool and continued the interview. That fear comes out totally unfounded! I am sure if I had overreacted, that overreaction would’ve been the face of steno, and that’s not cool!
Each stenographer is like an ambassador for who we are and what we do. A big part of what I do is getting to the bottom of things and communicating the truth about them so that each of us can go forward and be knowledgeable when the people we work with, judges or lawyers, bring this stuff up. Many of them already know we’re the best there is. The rest are just waiting for you. Your actions and excellence change the future every day. I got my five seconds of fame. Go get yours!
Addendum:
Sometime after the publishing of this article, the VICE story that I linked was locked on their website. You must select your TV provider to gain access. Also, I later learned Alzo actually aced the quiz. The reason he had trouble was because the sentence was not AAE / proper grammatically.
Let’s just get to the point. There is a study to be published in the linguistic journal Language in June 2019. Stenonymous covered this immediately. Succinctly the study showed that court reporters in the Philadelphia area were pretty inaccurate when dealing with the dialect of African American English. We had some suspicions about potential inaccuracy in the way the news was reporting it, and kept an eye out for information as it developed.
In early March, we came across new articles which identified one of the hard-working linguists on the study, Taylor Jones. Upon review of Mr. Jones’s blog — soon to be Dr. Jones as far as we’re aware — we reached out and he responded to everything we had to ask.
Though we haven’t yet gotten to see the study, between correspondence with Jones, review of his blog, and review of media coverage on the topic, we have some conclusions to present:
The court reporters were reporters working in court.
It’s true that stenographic court reporters were used.
The trials were not testing the reporters’ real-time accuracy, and participants were given as much time as they wanted to transcribe.
The accuracy of sentences was only 59.5% correct. When measuring word-for-word accuracy the accuracy was as much as 82.9%. Obviously, our stenographer training measures word-to-word accuracy.
Small “errors” were not counted as errors, such as if a speaker said “when you tryna go to the store?” Trying to and tryin’ to would both be counted as correct. An error would be “when he tries to go.” So the errors, as best I can tell, would fall in line with what NCRA says constitutes an error.
Misunderstandings come from a number of different sources, including common phonetic misunderstandings and dialect-motivated misunderstandings as discussed in William Labov’s Principles of Linguistic Change trilogy. While Jones himself said bias cannot be ruled out, there are a number of syntactical and accent-related issues that may honestly be a challenge for court reporters and the average judge, juror, or listener.
There were over 2,200 observations done in this study. 83 statements multiplied by 27 court reporters.
Now for some interesting highlights from my exchange with Jones:
African American English is not wrong. It is not slang. It has grammar and structure. It’s not slang, Ebonics, or street talk.
The people that conducted the study are not accusing court reporters of doing anything wrong. In fact, in my conversation with Jones, he was supportive of a human stenographer over an AI or automatic transcription because we still carry a far greater accuracy than those alternatives.
So here is where we are: We’ve got a piece of evidence from the linguistic community that there is an area we can improve on. I had briefly been in touch with a Culture Point representative who said they can work with organizations around the country on their transcription suite package, and that the budget for the workshop varies dependent on modality and class size.
We should all do our best to incorporate these ideas into our work and training. If you are a state or national association, don’t shy away from the opportunity to dive in and develop training surrounding different dialects, or even fund studies to seek out these deficiencies. If you are a working reporter, don’t be afraid to ask for a repetition. You are the guardian of an accurate and true record, and our work collectively can impact people’s lives and fortunes.
Short last note, I apologize to my readers and to Mr. Jones. I had promised my readers I’d get this article out and the email exchange out much sooner. I feel this is important and want to be a part of spreading the message that we can always do better. Though the initial response by Mr. Jones was March 8, I was unable to get this draft out until April 2. For that, I am sorry.
May 23, 2019 update: This came up in the news again and another person brought to my attention this draft of the study made available before its publication in the Language journal. It was noted by that person that the reporters were asked to paraphrase what was said, and that we do not interpret. My understanding and memory from my email with Jones is that they were asked to transcribe and interpret, and that at least one participant transcribed incorrectly but interpreted perfectly.
June 6, 2019 update:
Philadelphia judges came together to discuss language access after the study. As of this article, it seems the solution would be more training for court personnel than having interpreters for different English dialects.
September 13, 2019 update:
Another article popped up, ostensibly on this same study. With great respect to those article writers, I believe the headline that white court reporters don’t get black testimony is incorrect. I also believe that the contention that this is slang or Ebonics is incorrect. When I wrote Jones he was very clear that AAE is not slang. It’s a dialect. It has rules. I do hope that people really read the work for what it is and not what they want it to be. People mishear things. Judges and juries mishear things. This study brings to light that even we, the people who care most about every word said, can mishear things, and that makes it very, very important to be situationally aware and ask for clarification when it is appropriate, like many of us do every day.
January 28, 2020 update:
It should be noted that Mr. Jones, presumably now Dr. Jones, is listed as a co-founder of Culture Point on LinkedIn.
Addendum:
After some time I had an interview with VICE about this study because I was identified as being a stenographic reporter with a lot of knowledge on it. I will say while, in my mind, it showed us we must do better, ultimately it confirmed that we are people’s best chance at being understood in the courtroom. The pilot study 1 showed regular people were about 40 percent accurate. The pilot study 2 showed lawyers were 60 percent accurate. We were about 80 percent accurate. Clearly, we all want 100 percent, but when you read that we’re twice as good as your average person at taking down this dialect, it changes the spin. Later on, a Stanford study showed that automatic speech recognition had 20 percent error rate in “white speech,” 40 percent error rate in “black speech,” and worse with African American English dialect. When I graded the AAE example on their site, I saw that if it had been a steno test, it would be 20/100! It’s our skill and dedication that keeps us top quality in making the record and broadcast captioning.
Some may have read one of several articles from various outlets such as the New York Times, Philly, or Trib that, in summary, basically stated there’s a study that will be published in the Language journal. This study took a couple dozen volunteers and had them transcribe recorded statements that the news articles described as black dialect, but which I have also heard referred to described as urban English or street talk. The volunteers did not do well, and there was a high percentage of inaccuracy.
NCRA and PCRA responded to these articles openly. They basically called the title of the article(s) provocative, and pointed out that this involved volunteers taking down recorded statements as opposed to a live courtroom setting. They seem to believe as I do, that this study shows the desperate need for highly trained stenographers in courts.
Succinctly, there are two things the news often gets wrong: Law and science. We are talking about both at the same time, so I’m willing to go out on a limb and say that there are probably some inaccuracies or misconceptions about the actual study. Anecdotally, I look back to correspondence I’ve had with a researcher of a concept coined benevolent sexism. I actually wrote Jin Goh, a researcher in that study, and Jin Goh basically said we need more studies for the study to be conclusive, and the media misrepresented the study. The results were interesting and honest, but they did not mean that being nice to people was sexist as some news reported.
So of course the first step in understanding a study would be to read it and decide if reaching out to its authors is necessary. So I reached out to the group that publishes the Language journal only to learn that the study itself isn’t going to be published until June 2019.
So what can we say at this juncture? The study had a fairly small sample size, as best I can tell, of 27 volunteers. I am not entirely sure if those volunteers were stenographic reporters as of writing. This isn’t uncommon. We are in a world with finite resources and funding, so studies often don’t have the kind of money you’d need to reach conclusive results on any one topic over the course of one study. We can also note that this is, as best as I can tell, one of the first studies of its kind, so while it has interesting results, we need to remind ourselves these results are not, to our knowledge, representative of multiple studies over years. We need to remind ourselves that some researchers showed us months ago that studies and the news stories about them can be worded in a way that gets clicks, but not in a way that informs the reader. For example, a study was recently conducted that showed jumping out of a plane without a parachute does not increase your chance of injury. The catch? They jumped out of a parked plane. They did this intentionally to remind us all that news on studies can be slanted or cause misconceptions.
So what should we do? In my opinion, there’s only one thing to do. Open our eyes to the fact that a scientific study was conducted, and it’s apparent that humans mishear things a lot! Continue to adapt to different accents in our training and work. Continue to push to provide the best service possible to all lawyers, litigants, and caption consumers. I do think there’s a lot to be said for our performance in real courtroom settings. We ask for repeats all the time to make sure that what people say is honestly and accurately reflected, and that’s something they probably couldn’t get into a lab or study as easily. Perhaps with time we could even conduct our own study, and maybe it would find that the stenographer mishears less than the average person. Perhaps we’d find our hearing is average. We don’t know. That’s the point of studies.
Bottom line: Don’t let this thing ruffle your feathers. I saw a lot of reporters spew a lot of vitriol over the articles, and in the end, the theme of the articles were not “stenographers are bad,” but more “humans mishear things and we should be mindful of this in the administration of our courts because if the transcribers aren’t hearing it then it is likely the lawyers and judges aren’t either.” We’re good at what we do, and we’re better off proving that than attacking linguists on Twitter. We are better off making sure our service is the best service lawyers and litigants can find, period. Truthfully, researchers give us valuable insight into what we do, but it is we who perform every day who know what’s at stake for the lawyers, litigants, and judges we serve.
As an aside, I understand the verbiage of the headlines upset some readers and I agree that this all could’ve been written more artfully. I myself have used descriptors to try to explain the issue as it is and make it more clear for anyone that cares to read.
UPDATE MARCH 5, 2019:
I am very excited to say another article was released which published the linguist’s name, Taylor Jones. Taylor Jones’s site has a lot of very specific examples that I think are eye opening and important for everyone to read and understand, including examples like, “when you tryna go to the store?” I am delighted to have come across Jones’s website and work, and will be reaching out for comment and clarification on this study to understand exactly what it is about and how reporters might improve training. Previously, I believed I’d have to wait until June to see the study. At a glance, according to a January 2019 blog post by Jones, it does appear that they utilized and/or surveyed Philadelphia court reporters that were actually working in the courts. It is stated that evaluated sentence-by-sentence, accuracy was just under 60%, and when evaluated word-by-word, accuracy was about 82%. Without having yet received comment from Jones, I can say I am incredibly impressed by the blog, and anyone with interest in this study and developing better verbatim records should definitely swing by it and read some of the stuff there. At first glance, this really may be more of an issue than I had believed, and I’d encourage every reader to keep an open mind. Notably, Jones states he has worked with Culture Point to come up with a training suite to address this issue.
April 2, 2019:
In order to be subscriber-friendly I have attached all future updates on this to a new a blog post.