When I first found out my good friend Joshua Edwards was creating the nonprofit online speaking club StenoMasters, I was excited. I wrote about it right away. If you read the FAQ, the intention is to keep the dues as low as possible. It’s not a source of personal enrichment. I consider it a community and a chance for us to come together.
In my view, we are headed into a period of time where it will be vital for the stenographic reporter and his or her family to pick up some speaking skills. There are so many forces in life that will demand your silence. A club like StenoMasters is going to give you a safe place to develop your voice so that when the times comes you’ll be ready. Please join me at the inaugural meeting. It’s free! Even if you just go to lurk or observe, you will be helping others find their voice by providing them with that audience that so many of us struggle to speak in front of. If you have the time on October 4, it’s worth it. See the flyer below!
There’s a lot of conjecture when it comes to automatic speech recognition (ASR) and its ability to replace the stenographic reporter or captioner. You may also see ASR referred to as NLP or natural language processing. An important piece of the puzzle is understanding the basics behind artificial intelligence and how complex problems are solved. This can be confusing for reporters because in any of the literature on the topic, there are words and concepts that we simply have a weak grasp on. I’m going to tackle some of that today. In brief, computer programmers are problem solvers. They utilize datasets and algorithms to solve problems.
What is an algorithm?
An algorithm is a set of instructions that tell a computer what to do. You can also think of it as computer code for this discussion. To keep things simple, computers must have things broken down logically for them. Think of it like a recipe. For example, let’s look at a very simple algorithm written in the Python 3 language:
Do not despair. I’m about to make this so easy for you.
Line one tells the computer to put the words “The stenographer is _.” on the screen. Line two creates something called a Stenographer, and the Stenographer is equal to whatever you type in. If you input the word awesome with a lowercase or uppercase “a” the computer will tell you that you are right. If you input anything else, it will tell you the correct answer was awesome. Again, think of an algorithm like a recipe. The computer is told what to do with the information or ingredients it is given.
What is a dataset?
A dataset is a collection of information. In the context of machine learning, it is a collection that is put into the computer. An algorithm then tells the computer what to do with that information. Datasets will look very different dependent on the problem that a computer programmer is trying to solve. As an example, for enhancing facial recognition, datasets may be comprised of pictures. A dataset may be a wide range of photos labeled “face” or “not face.” The algorithm might tell the computer to compare millions of pictures. After doing that, the computer has a much better idea of what faces “look like.”
What is machine learning?
As demonstrated above, algorithms can be very simple steps that a computer goes through. Algorithms can also be incredibly complex math equations that help a computer analyze datasets and decide what to do with similar data in the future. One issue that comes up with any complex problem is that no dataset is perfect. For example, with regard to facial recognition, there have been situations with almost 100 percent accuracy with lighter male faces and only 80 percent accuracy with darker female faces. There are two major ways this can happen. One, the algorithm may not accurately instruct the computer on how to handle the differences between a “lighter male” face and a “darker female” face. Two, the dataset may not equally represent all faces. If the dataset has more “lighter male” faces in this example, then the computer will get more practice identifying those faces, and will not be as good at identifying other faces, even if the algorithm is perfect.
Artificial intelligence / AI / voice recognition, for purposes of this discussion, are all synonymous with each other and with machine learning. The computer is not making decisions for itself, like you see in the movies, it is being fed lots of data and using that to make future decisions.
Why Voice Recognition Isn’t Perfect and May Never Be
Computers “hear” sound by taking the air pressure from a noise into a microphone and converting that to electronic signals or instructions so that it can be played back through a speaker. A dataset for audio recognition might look something like a clip of someone speaking paired with the words that are spoken. There are many factors that complicate this. Datasets might be focused on speakers that speak in a grammatically correct fashion. Datasets might focus on a specific demographic. Datasets might focus on a specific topic. Datasets might focus on audio that does not have background noises. Creating a dataset that accurately reflects every type of speaker in every environment, and an algorithm that tells the computer what to do with it, is very hard. “Training” the computer on imperfect datasets can result in a word error rate of up to 75 percent.
This technology is not new. There is a patent from 2000 that seems to be a design for audio and stenographic transcription to be fed to a “data center.” That patent was assigned to Nuance Communications, the owner of Dragon, in 2009. From the documents, as I interpret them, it was thought that 20 to 30 hours of training could result in 92 percent accuracy. One thing is clear: as far back as 2000, 92 percent accuracy was in the realm of possibility. As recently as April 2020, the data studied from Apple, IBM, Google, Amazon, and Microsoft was 65 to 80 percent accuracy. Assuming, from Microsoft’s intention to purchase Nuance for $20 billion, that Nuance is the best voice recognition on the market today, there’s still zero reason to believe that Nuance’s technology is comparable to court reporter accuracy. Nuance Communications was founded in 1992. Verbit was founded in 2016. If the new kid on the block seriously believes it has a chance of competing, and it seems to, that’s a pretty good indicator that Nuance’s lead is tenuous, if it exists at all. There’s a list of problems for automation of speech recognition, and even though computer programmers are brilliant people, there’s no guarantee any of them will be “perfectly solved.” Dragon trains to a person’s voice to get its high level of accuracy. It simply would not make economic sense to have hours of training a software to everyone who is going to speak in court forever until the end of time, and the process would be susceptible to sabotage or mistake if it was unmonitored and/or self-guided (AKA cheap).
This is all why legal reporting needs the human element. We are able to understand context and make decisions even when we have no prior experience with a situation. Think of all the times you’ve heard a qualified stenographer, videographer, or voice writer say “in 30 years, I’ve neverseen that.” For us, it’s just something that happens, and we handle whatever the situation is. For a computer that has never been trained with the right dataset, it’s catastrophic. It’s easy, now, to see why even AI proponents like Tom Livne have said that they will not remove the human element.
Why Learning About Machine Learning Is Important For Court Reporters
Machine learning, or applications fueled by machine learning, are very likely to become part of our stenographic software. If you don’t believe me, just read this snippet about Advantage Software’s Eclipse AI Boost.
Don’t get out the pitchforks. Just consider what I have to blog.
If you’ve been following along, you’ve probably figured out, and it pretty much lays it out here, that datasets are needed to train “AI.” There are a few somewhat technical questions that stenographic reporters will probably want answered at some point:
Is this technology really sending your audio up to the Cloud and Google?
Is Google’s transcription reliable?
How securely is the information being sent?
Is the reporter’s transcription also being sent up to the Cloud and Google?
The reasons for answering?
The sensitive nature of some of our work may make it unsuitable for being uploaded. To the extent stuff may be confidential, privileged, or ex parte, court reporters and their clients may simply not want the audio to go anywhere.
Again, as shown in “Racial disparities in automated speech recognition” by Allison Koenecke, et al., Google’s ASR word error rate can be as high as 30 percent. Having to fix 30 percent of a job is a frightening possibility that could be more a hindrance than a help. I’m a pretty average reporter, and if I don’t do any defining on a job, I only have to fix 2 to 10 percent of any given job.
If we assume that everyone is fine with the audio being sent to the cloud, we must still question the security of the information. I assume that the best encryption possible would be in use, so this would be a minor issue.
The reporter’s transcription carries not only all the same confidential information discussed in point 1, but also would provide helpful data to make the AI better. Reporters will have to decide whether they want to help improve this technology for free. If the reporter’s transcription is not sent up with the audio, then the audio would only ostensibly be useful if human transcribers went through the audio, similar to what Facebook was caught doing two years ago. Do we want outside transcribers having access to this data?
Our technological competence changes how well we serve our clients. Nobody reading this needs to become a computer genius, but being generally aware of how these things work and some of the material out there can only benefit reporters. In one of my first posts about AI, I alluded to the fact that just because a problem is solvable does not mean it will be solved. I didn’t have any of the data I have today to assure me that my guess was correct. But I saw how tech news was demoralizing my fellow stenographers, and I called it as I saw it even though I risked looking like an idiot.
It’s my hope that reporters can similarly let go of fear and start to pick apart the truth about what’s being sold to them. Talk to each other about this stuff, pros and cons. My personal view, at this point, is that a lot of these salespeople saw a field with a large percentage of women sitting on a nice chunk of the “$30 billion” transcription industry, and assumed we’d all be too risk averse to speak out on it. Obviously, I’m not a woman, but it makes a lot of sense. Pick on the people that won’t fight back. Pick on the people that will freeze their rates for 20 or 30 years. Keep telling a lie and it will become the truth because people expect it to become the truth. Look how many reporters believe audio recording is cheaper even when that’s not necessarily true.
Here’s my assumption: a little bit of hope and we’ve won. Decades ago, a scientist named Richter did an experiment where rats were placed in the water. It took them a few minutes to drown. Another group of rats were taken out of the water just before they drowned. The next time they were submerged, they swam for hours to survive. We’re not rats, we’re reporters, but I’ve watched this work for humans too. Years ago, doctors estimated a family member would live about six more months. We all rallied around her and said “maybe they’re wrong.” She went another three years. We have a totally different situation here. We know they’re wrong. Every reporter has a choice: sit on the sideline and let other people decide what happens or become advocates for the consumers we’ve been protecting for the last 140 years, before the stenotype design we use today was even invented. People have been telling stenographers that their technology is outdated since before I was born, and it’s only gotten more advanced since that time. Next time somebody makes such a claim, it’s not unreasonable for you to question it, learn what you can, and let your clients know what kind of deal they’re getting with the “new tech.”
Addendum 4/27/21:
Some readers checked in with the Eclipse AI Boost, and as it was relayed to me, the agreement is that Google will not save the audio and will not be taking the stenographic transcriptions. Assuming that this is true, my current understanding of the tech is that stenographers would not be helping improve the technology by utilizing this technology unless there’s some clever wordplay going on, “we’re not saving the audio, we’re just analyzing it.” At this point, I have no reason to suspect that kind of a game. In my view, our software manufacturers tend to be honest because there’s simply no truth worth getting caught in a lie over. The worst I have seen are companies using buzzwords to try to appease everyone, and I have not seen that from Advantage.
Admittedly, I did not reach out to Advantage myself because this was meant to assist reporters with understanding the concepts as opposed to a news story. But I’m very happy people took that to heart and started asking questions.
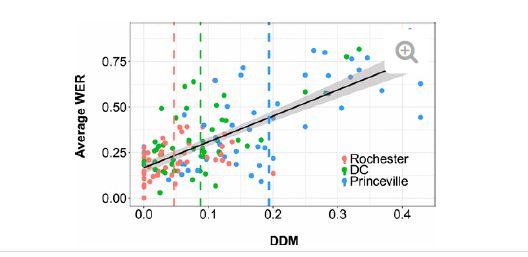
As a stenographic court reporter, I have been amazed by the strides in technology. Around 2016, I, like many of you, saw the first claims that speech recognition was as good as human ears. Automation seemed inevitable, and a few of my most beloved colleagues believed there was not a future for our amazing students. In 2019, the Testifying While Black study was published in the Language Journal, and while the study and its pilot studies showed that court reporters were twice as good at understanding the AAVE dialect as your average person, even though we have no training whatsoever in that dialect, the news media focused on the fact that we certify at 95 percent and yet only had 80 percent accuracy in the study. Some of the people involved with that study, namely Taylor Jones and Christopher Hall, introduced Culture Point, just one provider that could help make that 80 percent so much higher. In 2020, a study from Stanford showed that automatic speech recognition had a word error rate of 19 percent for “white” speakers, 35 percent for “black” speakers, and “worse” for speakers with a high dialect density. How much worse?
The .75 on the left means 75 percent. DDM is the dialect density. Even with fairly low dialect density, we’re looking at over 50 percent word error rate.
75 percent word error rate in a study done three or four years after the first claim that automatic speech recognition had 94 percent accuracy. But in all my research and all that has been written on this topic, I have not seen the following point addressed:
What Is An Error?
NCRA, many years ago, set out guidelines for what constituted an error. Word error guidelines take up about a page. Grammatical error guidelines take up about a page. What this means is that when you sit down for a steno test, you’re not being graded on your word error rate (WER), you’re being graded on your total errors. We have decades of failed certification tests where a period or comma meant a reporter wasn’t ready for the working world yet. Even where speech recognition is amazing on that WER, I’ve almost never seen appreciable grammar, punctuation, Q&A, or anything that we do to make the transcript readable. It’s so bad that advocates for the deaf, like Meryl Evans, refer to automatic speech recognition as “autocraptions.”
Unless the bench, bar, and captioning consumers want word soup to be the standard, the difference in how we describe errors needs to be injected into the discussion. Unless we want to go from a world where one reporter, perhaps paired with a scopist, completes the transcript and is accountable for it, to a world where up to eight transcribers are needed to transcribe a daily, we need to continue to push this as a consumer protection issue. Even where regulations are lacking, this is a serious and systemic issue that could shred access to justice. We have to hit every medium possible and let people know the record — in fact, every record in this country — could be in danger. The data coming out is clear. Anyone selling recording and/or automatic transcription says 90-something percent accuracy. Any time it’s actually studied? Maybe 80 percent accuracy, maybe 25; maybe they hire a real expert transcriber, or maybe they outsource all their transcription to Kenya or Manila. Perception matters; court administrators are making industry-changing decisions based on the lies or ignorance of private sector vendors.
The point is recording equipment sellers are taking a field which has been refined by stenographic court reporters to be a fairly painless process where there are clear guidelines for what happens when something goes wrong, adding lots of extra parts to it, and calling it new. We’ve been comparing our 95 percent total accuracy to their “94 percent” word error rate. In 2016, perhaps there were questions that needed answering. This is April 2021, there’s no contest, and proponents of digital recording and automatic transcription have a moral obligation to look at the facts as they are today and not what they’d like them to be.
We try to keep political stuff from being published here unless it’s educational, about court reporting, or about the industry. I’ve been pretty good about this. Commentators have been great about it. The occasional guest writer has been amazing with it. This topic touches with politics, but it’s not strictly political, so it should be fun to learn about.
It’s established that the United Kingdom, United States, China, Russia and several other countries view the internet as, more or less, another theater of war. They’ve had operatives and people hired to create fake posts, false comments, and advance the interests and ideas of the government. The prices reported? Eight dollars for a social media post, $100 for ten comments, and $65 for contacting a media source. In the case of China, they’re reportedly working for less than a dollar. If the host country allows it, you have trolls for hire.
So in the context of stenography and the court reporting industry, seems like whenever we get into the news, there are regular comments from regular people, such as “why not just record it?” Typical question. Anyone would ask this question. There are fun comments like “Christopher Day the stenographer looks like he belongs on an episode of Jeopardy.” Then there are comments that go above and beyond that. They make claims like — well, just take a look.
“…I gonna tell you that in modern technology we can record something like court testimony for hundreds of years back very easily…” “…the technology is smarter every single second…” “…if you store data in the digital format we can use an AI to extract the word from the voice in the data, it will be very accurate so much so the stenographer loses their jobs.” Wow! Lose our jobs? I felt that in my heart! Almost like it was designed to hurt a stenographer’s feelings. Right?
We can store the video for hundreds of years? Maybe. But consider that text files, no matter what way you swing it, are ten times smaller than audio files. They can be thousands of times smaller than video files. Take whatever your local court is paying for storage today and multiply that by 8,000. Unless we want a court system that is funded by advertisements a la Youtube, the taxpayer will be forced to cough up much more money than they are today. That’s just storing stuff.
The technology is getting smarter every second? No, not really. Whenever it’s analyzed by anybody who isn’t selling it, it’s actually pretty dumb and has been that way for a while. Take Wade Roush’s May 2020 article in the Scientific American (pg 24). “But accuracy is another matter. In 2016 a team at Microsoft Research announced that it had trained its machine-learning algorithms to transcribe speech from a standard corpus of recordings with record-high 94 percent accuracy. Professional human transcriptionists performed no better than the program in Microsoft’s tests, which led media outlets to celebrate the arrival of ‘parity’ between humans and software in speech recognition.”
“…And four years after that breakthrough, services such as Temi still claim no better than 95 percent — and then only for recordings of clear, unaccented speech.” Roush concludes, in part, “ASR systems may never reach 100 percent accuracy…” So technology isn’t getting smarter every second. It’s not even getting smarter every half decade at this point.
“…we can use an AI to extract the word from the voice in the data…” This technology exists, kind of, but perfecting it would be like perfecting speech recognition. Nobody’s watching 500 hours of video to see if it accurately returns every instance of a word. Ultimately, you’re paying for the computer’s best guess. Sometimes that’ll be pretty good. Sometimes you won’t find the droid you’re looking for.
Conclusion? This person’s probably not in the media transcoding industry, probably doesn’t know what they’re talking about, and is in all likelihood a troll. Were they paid to make that comment? We don’t know. But I think it’s time to realize that marketplaces are ripe for deception and propaganda. So when you see especially mean, hateful, targeted comments, understand that there’s some chance that the person writing the comment doesn’t live in the same country as you and doesn’t actually care about the topic they’re writing about. There’s some chance that person was paid to spread an opinion or an idea. Realizing this gives us power to question what these folks are saying and be agents of truth in these online communities. Always ignoring trolling leads to trolling leading the conversation. So dropping the occasional polite counterview when you see an obvious troll can make a real impact on perception. The positive perception of consumers and the public is what keeps steno in business.
The best part of all this? You can rest easier knowing some of those hateful things you see online about issues you care about are just hired thugs trying to divide us. If a comment is designed to hurt you, you might just be talking to a Russian operative.
Addendum:
I understand readers will be met with the Scientific American paywall. I would open myself up to copyright problems to display the entire article here. If you’d like to speak out against the abject tyranny of paywalls, give me money! I’m kidding.
We’re in an interesting time. Pretty much anywhere you look there are job postings for digital reporters, articles with headlines talking about our replacement, articles with headlines talking about our angst. Over time, brilliant articles from people like Eric Allen, Ana Fatima Costa, Angie Starbuck (bar version), and Stanley Sakai start to get buried or appear dated when, in actuality, not much has changed at all. They’re super relevant and on point. Unfortunately, at least for the time being, we’re going to have to use our professional sense, think critically, and keep spreading the truth about ourselves and the tech we use.
One way to do that critical thinking is to look squarely at what is presented and notice what goes unmentioned. For example, look back at my first link. Searching for digital reporting work, ambiguous “freelance” postings come up, meaning stenographer jobs are actually branded as “digital” jobs. District courts seeking a stenographer? Labeled as a digital job. News reporters to report news about court? Labeled as a digital job. No wonder there’s a shortage, we’re just labeling everything the same way and expecting people who haven’t spent four decades in this business to figure it out. In this particular instance, Zip Recruiter proudly told me there were about 20 digital court reporter jobs in New York, but in actuality about 90 percent were mislabeled.
Another way to do it is to look at contradictions in a general narrative. For example, we say steno is integrity. So there was an article from Lisa Dees that shot back and said, basically, any method can have integrity. Can’t argue there. Integrity is kind of an individual thing. But to get to the conclusion these things are equal, you have to ignore a lot of stuff that anyone who’s been working in the field a while knows. Stenography has a longer history and a stronger culture. With AAERT pulling in maybe 20 percent of what NCRA does on the regular, who has more money going into ethics education? Most likely stenographers. When you multiply the number of people that have to work on a transcript, you’re multiplying the risk of one of those people not having integrity. We’re also ignoring how digital proponents like US Legal have no problem going into a courtroom and arguing that they shouldn’t be regulated like court reporters because they don’t supply court reporting services. Even further down the road of integrity, we know from other digital proponents that stenography is the gold standard (thanks, Stenograph) and that the master plan for digital proponents is to use a workforce that is not highly trained. I will totally concede that these things are all from “different” sources, but they all point to each other as de facto experts in the field and sit on each other’s boards and panels. It’s very clear there’s mutual interest. So, again, look at the contradictions. “The integrity of every method is equal, but stenography is the gold standard, but we are going to use a workforce with less training.” What?
Let’s get to how to talk about this stuff, and for that, I’m going to leave an example here. I do follow the court reporting stuff that gets published by Legaltech News. There’s one news reporter, Victoria Hudgins, who has touched on steno and court reporting a few times. I feel her information is coming mostly from the digital proponents, so in an effort to provide more information, I wrote:
“Hi Ms. Hudgins. My name’s Christopher Day. I’m a stenographer in New York. I follow with great interest and admiration most of your articles related to court reporting in Legal Tech News [sic]. But I am writing today to let you know that many of the things being represented to you by these companies appear false or misleading. In the August 24 article about Stenograph’s logo, the Stenograph offices that you were given are, as best I can tell, a stock photo. In the September 11 article about court reporter angst, Livne, says our field has not been digitized, but that’s simply not true. Court reporter equipment has been digital for decades. The stenotype picture you got from Mr. Rando is quite an old model and most of us do not use those anymore. I’m happy to send you a picture of a newer model, or share evidence for any of my statements in this communication.
Our position is being misrepresented very much. We are not worried so much about the technology, we are more worried that people will believe the technology is ready for prime time and replace us with it without realizing that it is not. Livne kind of admitted this himself. In his series A funding, he or Verbit stated that the tech was 99 percent accurate. In the series B funding he said Verbit would not get rid of the human element. These two statements don’t seem very compatible.
How come when these companies are selling their ASR, it’s “99 percent” or “ready to disrupt the market,” but when Stanford studied ASR it was, at best, 80 percent accurate?
Ultimately, if the ASR isn’t up to the task, these are transcription companies. They know that if they continue to use the buzzwords, you’ll continue to publish them, and that will draw them more investors.
I am happy to be a resource on stenographic court reporting technology, its efficiency, and at least a few of the things that have been done to address the shortage. Please feel free to reach out.”
To be very fair, because of the limitations of the website submission form, she didn’t get any of the links. But, you know, I think this stands as a decent example of how to address news people when they pick up stories about us. They just don’t know. They only know what they’re told or how things look. There will be some responsibility on our part to share our years of experience and knowledge if we want fair representation in media. It’s the Pygmalion effect at work. Expectations can impact reality. That’s why these narratives exist, and that is why a countering narrative is so important. Think about it. When digital first came it was all about how it was allegedly cheaper. When that turned out not to be true, it became a call for stenographers to just see the writing on the wall and acknowledge there is a shortage and that there is nothing we can do about it. Now that’s turning out not to be true, we’re doing a lot about it, and all we have left is to let those outside the industry know the truth.
Addendum:
A reader reminded me that Eric Allen’s article is now in archive. The text may be found here. For context purposes, it came amid a series of articles by Steve Townsend, and is an excellent example of what I’m talking about in terms of getting the truth out there.