I recently received a message about my student loans. It used an address I am familiar with and looked possibly legitimate at first glance.
Of course, my student loans have been paid for over a decade now.
Let this be a warning to all steno students: There are scams going on that may use addresses you are familiar with. Always double check the sender and DO NOT let the promise of debt forgiveness push you into FOMO (fear of missing out).
Scammers prey on human emotions. Don’t let them prey on yours.
Checking the sender can help identify scams using Hotmail and Gmail.
This one has some personal meaning to me. I suffered from a wrist injury during my stenographic education. I used all of my willpower, support system, and resourcefulness to overcome it.
I feel she’s come up with a unique idea that could benefit our field in unforeseeable ways. For example, consider that when I first started writing, I had no idea that this blog would evolve and capture the attention that it has. No one in their right mind would (joke intended).
If you’ve been enjoying Stenonymous.com, you’re in good company.
In brief, she’s going to use a PNGTuber style to document her student journey, and has interesting future plans to capture brain activity via EEG, among other things.
Love or hate the art style, this is an interesting proposition. Publishing data like that may be the first step in connecting us with the scientific community and exploring new avenues of understanding what we do.
As a runaway theoretical example, say we were one day able to say with some data backing us that stenotyping was therapeutic in some way. Well, Stenograph or any of them could market that and open this technology up to many millions of people. Once people saw money in what we do, well, we probably wouldn’t be just a $3 billion industry anymore. The legal transcript demand might be fixed to an extent, but I’ve always been a firm believer in the idea that there are enough people with enough disposable income that we could market stenographic services more to the general public, corporate boards, and union meetings. For many, our fees are trivial, and the benefits of having a record vary from operation to operation.
To say it another way, our visibility problem would evaporate. This may seem farfetched to you, but of course it would, it’s a new idea.
We have a long history of helping each other. Dom Tursi taught many New Yorkers that and we’ve carried it forward throughout our lives. I think today should be no different. If you have the ability, let’s accelerate this project. If not because it’s the right thing to do, then because it brings a media style I have not seen in this field, which could bring more bright minds to “our side” of the reporting spectrum.
And Alejandra, let us know when we can buy some equity in Astrid Spirals LLC.
P.S.
(Disclosure: I had a discussion with Alejandra and another young man some time ago. When they talked about some of the science stuff they were looking into, my gut told me they were onto something, and that’s a big driver for my views today.)
(Note: If these types of submissions become more regular, perhaps we will do a monthly or weekly piece with all contribution-requesting projects. What do you all think?)
Addendum:
Some Stenonymous readers informed me the link was not working. I have tried to correct the issue. You may also try this one.
Virtual Vision Board Party 2023. Steno Vision with Carrie Hewerdine, Deneé Vadell, and Stephanie Hicks. Links Below.
If I asked you what vision you have for yourself, what would you say?
Last December, Deneé Vadell, Stephanie Hicks, and Carrie Hewerdine hosted a virtual vision board party where students and reporters created vision boards while uplifting music played. Some people used posterboard and magazine clippings, while others created theirs electronically. I ended up doing both and loving the experience. Tunes were jamming, people were vibing and leaning side to side as they got creative with their colleagues.
Passing a specific speed, graduating, becoming certified, paying off debts, traveling, and living a healthy and more balanced life are some of the visions that became realities for some of the attendees.
What do you envision for yourself?
Vision Board by Chris DeGrazio
I remember the first time I learned what a vision board was. I thought the idea was silly. I’ve always respected and appreciated the value and motivation they provide others, but I never saw myself as someone who would be into that sort of thing.
What appealed to me was the social element. Being able to spend time with friends and be creative? Heck yeah!
If you’re able to attend this year, please consider joining the Facebook group “Steno Vision by StenoFluencer” and share pics of a vision board you’ve created in the past. We’d love to see! Maybe you can share a story of how a vision board has helped you accomplish a specific goal in your life.
May your year be filled with insights. May your health be good. May your visions become realities.
– Chris DeGrazio
Vision Board by Aralin Camacho, RPR
The vision board party was amazing and very unique. Deneé has a special way of always making people feel comfortable and cheering them on.
One of my goals was to earn my RPR which Deneé helped me with by encouraging me, we were determined to accomplish our goals, and I was able to become certified in January 2023.
I loved the way everyone collaborated together to make goals a reality, which was lovely because everyone was in the comfort of their own home but on camera together while Denee’ provided great music to set the tone for a magical evening.
I loved it and would definitely continue to attend these because Deneé’s energy is magnetic!
– Aralin Camacho, RPR
My board is in a frame next to my makeup station. I look at it every day and repeat out loud the goals I plan to achieve. It makes me smile, looking at the creativity I put into this special creation, knowing my mantra is coming to fruition. P.S. I still listen to the music you played for inspiration!
– Lisa Neal, RPR
I was excited about the vision board party with Deneé and Stephanie. I had a lot of fun. I passed my CCRA CCG exam. And paid off credit card debt.
– Felicia Price, CCG
Vision Board by Amanda Lundberg, RPR, CRC, NM CSR #567
My virtual vision board helped me focus on the upcoming year. I’ve had many local adventures, focused on improving my skills, and started volunteering at our local animal shelter. Next year I’m going to get to the travel part!
– Amanda Lundberg, RPR, CRC, NM CSR #567
It’s great to see your goals that are in your head and heart visualized on the vision board. It motivates you into action to complete the tasks needed to accomplish your goals.
– Bernice Whitlock
Vision Board by McKalie Bellew, RPR.Vision Board by McKalie Bellew, RPR
In December of 2022, I attended a virtual vision board party hosted by Deneé Vadell, or StenoFluencer. The vision board party was such an amazing experience and confidence boost. My vision board manifested for me to obtain my RSR, RPR and my Arizona State license. In March I obtained my RSR, in April I obtained my Washington state license, in July I obtained my RPR and in October I obtained my Arizona state license. I kept my vision board where I could always see it in my office at home and it was a great motivator. Going through the process of finding all the words of encouragement and affirmation to add to my board was so fulfilling imagining how great I wanted to be and knew I could be.
I love doing anything with the steno community, virtual or in person, and being surrounded by like-minded friends working toward a career in this profession made it that much more memorable and meaningful! I can’t wait to see what I whip up for my vision board for 2024!
– McKalie Bellew, RPR
After attending the virtual vision board party, I finally had enough courage to make the change in my career that I’ve always been scared to do. I went from freelance to court and passed the state court test. Never let fear stop you from achieving your goals! Thank you so much for all that you do to promote Steno.
– Anna Monchas-Gorvitz
Vision Board by Stephanie Hicks, RMR
This event was everything 👏🏽 Deneé Vadell’s playlist + Carrie Hewerdine’s energy + everyone’s positive energy and focus on the task at hand 🙌🏽 My vision board turned out amazing!! Can’t wait to add to it over the course of the year and accomplish all of my goals! 🔥🔥❤️
– Stephanie Hicks, RMR
Vision Board by Margary Rogers, RPR, CRI
Last year’s vision board party gave me a chance with like-minded individuals to sit quietly and allow visions of the future to seep below the surface of just thinking about it. I kept focusing on more time for me, and I got just that. Several vacations during the year, but the same amount of money billed as the previous year. So win-win.
– Carrie Hewerdine, RDR
Vision Board by Deneé Vadell, RPR
Vision boards help you visualize your success. By looking at your vision board daily, you immerse yourself in a visual representation of what you want or hope to achieve. This helps create a positive and powerful image in your mind while making you believe in your ability to achieve your goals.
Once I started creating vision boards, the game changed! In the last 5 years, I put goals & dreams on my vision board such as becoming a homeowner, getting my RPR, getting a black luxury car, having a destination wedding, traveling more, combining love and money, and saving money. I’ve achieved all of the above! I truly believe in the famous quote, “Write the vision and make it plain.”
I realized that vision boards changed my life and I wanted to share it with the steno community and anyone else who was interested, so I hosted a virtual vision board party for stenographers and also had them invite friends and family to join in with them.
I asked my steno bestie, Stephanie Hicks, RMR, if she would host it with me and then I asked Carrie Hewerdine, RDR, if she would be our special guest. The party was so successful. I plan on hosting one every year even if I don’t need to create a new board.
The next Virtual Vision Board Party will be held via Zoom on December 16th, 2023, from 7:00-10:00 p.m. ET. You can register for free at this link below.
Had the privilege of reviewing this article in the Broadway News about our very own Joshua Edwards and the company he co-owns, StenoCaptions LLC. There’s a paywall and I must respect the owners’ copyright by law and ethics, so I can only really give snippets and commentary. But stenographers everywhere are making the news, and that’s a wonderful thing.
“This year’s unscripted ceremony marked Edwards’ fifth Tonys and — what he says — was the most liberating of them all.” In brief, because of solidarity with the writer strike, the event was unscripted. As stated in the article, reported by Ruthie Fierberg, the script is usually 200 pages long. That script is used for captioning preparation. This year, Joshua had to go in without it.
The article turns out to be a real teaching moment. Joshua explained briefs and dictionaries, as well as talking about the importance of accessibility. Towards the end of the article, he’s quoted as saying “the people who must demand a live human captioner are the consumers who depend on us, our accuracy and reliability.” I find this to be very true. If consumers do not take a stand, they will be given whatever slop providers want to give.
I don’t know if you’ll end up reading this, but thank you, Joshua, for representing and showing people that stenography is modern, capable, and ready to meet the demands of captioning consumers. There have been many in modern times that have tried to obfuscate that truth about stenographers, court reporters and captioners alike. Unfortunately for them, the truth remains the truth whether you like it or not.
And thank you, Broadway News and Ruthie Fierberg, for a great article.
If anybody has a business, nonprofit, or media enterprise to promote in the court reporting, captioning, or stenotype services market, please consider taking the time to fill out about five questions in today’s survey.
The idea is pretty simple. I’m getting better and better at creating or brainstorming ads that drive engagement. With an actual budget for this activity, we could be promoting stenotype services to the general public and lawyers, and we could run ads 24/7 and direct consumers to the businesses that fund the advertising, perhaps via a public list or rating service. We could even perform regional marketing for businesses with a big enough budget. I can also pass my funders tips and tricks on marketing for their own social media pages, particularly as I learn more. I’ll find what works and what flops, and everybody funding the endeavor will benefit from it. If the budget gets really big, perhaps monthly ads could also be taken out in the law publications around the United States.
At this point, I’m still in the research stage of the idea, but my gut instinct to keep this sustainable but inexpensive would be each business paying about $200 a month, With just 8 businesses or sole proprietors in the group, we could run pro-stenographic social media ads year-round, which I guesstimate would generate somewhere in the ballpark of 120,000 engagements. That’s 120,000 chances per year to reach potential customers or audience members. According to at least one market research report, there are at least 3,000 businesses in our field. Just 2% of those businesses paying into it could generate 120,000 engagements a month. That’s steno coming into the feeds of over 1.4 million profiles a year.
I’m willing to change things up a bit, make the front page of Stenonymous.com a tad bit more corporate friendly, and try to attract more eyes to the businesses that sponsor the ads. I tried to raise the alarms on the corporate fraud. It’s not bringing in the funding needed to continue investigating and generating public interest. It’s time to do something different and try to bring more money into your businesses and get more eyes on your hard work. If the funders are serious about this, we could even do away with Stenonymous branding entirely, but I’d need commitments.
I have something of a theory related to our field and human interaction that might shed some light on this idea. I’ve noted that people have an innate need to be heard. How many times have we watched someone speak in court against their lawyer’s advice? Have you ever seen a child or adult with something to say and nobody who’ll listen? They become depressed, frustrated, anxious, angry. We know people need to be heard. What does the market do? It solves needs. Who better to solve the human need to be heard than the captioners, court reporters, and stenographers of the world? Now, stenographers can be very expensive, and there’s no real getting around that because every hour on our machine can mean 1 to 2 hours of transcription. But let’s say we started opening our stenotype service firms up to the public at an hourly rate? Say your page rate is $5.00 and you know you get about 60 pages an hour. You can offer $300/speaking hour stenotype services to the public without losing a dime. The general public could also book reporters on weekends and create additional income.
Economically, I would hope for a few things. 1. The constant barrage of advertisement for the public would educate more people about this field and bring more people into it, ending the shortage decisively. 2. The listing could create a kind of digital marketplace that educates consumers and helps them find the best businesses™️. 3. The barrage of marketing could bring investors onto the field looking to help businesses like yours grow and service more people (more $$$). 4. The funders might be able to network with each other to cover areas hit hardest by shortage, as long as they respect antitrust law, particularly against price fixing. 5. The increase in demand for the gold standard will draw more investors to open schools, which can then use the expected retirees over the next decade to educate the next generation. 6. We could set up a feedback system where businesses could receive or view feedback from consumers, enabling businesses to improve their business and create a more competitive marketplace. 7. The number of funders could grow to the point where we are able to offer group benefits to funders, such as legal referrals, where allowed by law. Many business owners have asked me questions about the law, which I’m happy to talk about but can’t give advice on, because I’m not a lawyer. Imagine a world where you could get that simple legal advice. 8. If the number of funders goes up, there is a very real possibility of locking the price at $200 rather than watching it soar with inflation, meaning fixed-cost advertising in a world with a lot of variables. 9. Diversifying income streams for “court reporting” (bringing in general consumers and getting out of the lawyer niche). 10. Captioners might benefit from more demand if more corporate boards and business owners know CART exists. How can consumers ask for something if they don’t know about it? 11. If wildly successful, scaling up to TV ads, podcasts, or more.
As an aside, we could also pump the market with speaking tips to help make our job easier. Joshua Edwards, creator of StenoMasters, is one of the best regional speakers around. I am quite hopeful that if I presented him with a budget, he’d help us educate the public. So much of the hassle from this job comes from speakers that don’t get what we do. We can make it easy for them.
I am in an interesting position. I’ve spent the last few years learning about this social media advertising stuff through firsthand experience. It would be a dream to use that to bring additional dollars to the market. I’m the man for the job. I’ve already shown my dedication to the futures of working reporters and our students. My site already gets thousands of visitors per month. Show the world we’re open for business, and we’ll be in business a long, long time.
So now it comes down to my audience. If you know businesses, suppliers, nonprofits, independent contractors, or schools that might help fund this initiative, please ask them to fill out the survey linked at the top. Thank you.
Ad data shared by Stenonymous.com in February 2023.
I attended the National Court Reporters Association Town Hall today with President Jason Meadors, and boy, am I glad I did. It gave me confidence that the association and its leaders are pushing hard to represent the interests of members. The entire session was almost exactly an hour, so there’s a lot to unpack.
Present at the meeting were, as stated, NCRA President Jason Meadors, Executive Director Dave Wenhold, Max Curry, a Past President and Chair of the A to Z committee, Annemarie Roketenetz, Director of Communications & PR, and Jocelynn Moore, Director of Government Relations. The meeting started off with a lengthy discussion from Max Curry about the A to Z program, and he took the time to explain where the program started and how it was completely revamped. According to Mr. Curry, A to Z began with about 50 boots-on-the-ground programs in the states. That fell away when the pandemic happened, and most programs closed. Programs in Texas, Tennessee, Minnesota, and California all went remote, which showed that the program could be done remotely. A new vision has come into place where the program can be done remotely and all of the resources can be centralized behind the program, with fewer boots-on-the-ground programs. Eight programs will be done a year, four asynchronous and four live. This is to capture the different kinds of learners — ones that can learn on their own AND people that need interactivity to succeed.
One of the truly exciting plans was for a landing page that can be centralized that brings people back to A to Z. NCRA is planning to reach out to organizations and associations to have them host a button or link to the landing page, creating a spiderweb or net that helps catch all the people that might be interested in this wonderful career and bring them back to the NCRA’s A to Z to give steno a try. They may ask firms to donate $5 to $10 of their Search Engine Optimization budget to help bring people to the landing page. NCRA President-Elect Kristin Anderson’s Houston President’s Party will act as a fundraiser for SEO dollars to ramp up advertising about court reporting and captioning as careers.
Lisa Dennison also spoke and informed us that 15 A to Z scholarships were given out at $750 per award. NCRA interacted with ASCA, the American School Counselor Association, getting school counselors’ contact information, adding them to a contact list, and getting them information about court reporting. It was mentioned that the communications team has been working on Instagram, QR Codes, and other ways to spread the message. Reliance donated money for student memberships for previous A to Z graduates, which helped grow association membership as well.
It was mentioned that NCRA continues to work with vendors such as Advantage, ProCAT, and Stenograph. The StenoCAT iPad app, iStenoPad, was also described as a way to simplify the logistics of getting stenotypes to participants.
It was explained that last year 295 students were picked up by A to Z. Max Curry clarified that some local programs do not coordinate with headquarters, so numbers from those programs are unavailable. Ms. Dennison asked that participant lists be sent to the NCRA so that better data can be compiled.
A quote by Brianna Coppola was shared. “I have never seen or heard of another ‘career test drive’ course. It really spotlights the encouragement within the community of reporters and their love for their jobs and dedication to the field.”
Dineen Squillante asked about the possibility of reaching out to departments of labor in each state. Lisa Dennison responded that it was something that could be looked into.
2022 Program Leaders and Speakers were thanked. It’s an extensive list, and I feel they deserve the recognition.
Ms. Dennison made it clear that the door was open to anyone that wanted to reach out on A to Z.
Annemarie Roketenetz talked a little bit about plants for Court Reporting & Captioning week, and a lot about the many endeavors of NCRA. She also mentioned that a number of press releases would be made, leading up to a larger press release that will link back to all the smaller ones. This is in line with dispatching our news and events regularly, and a very smart move on NCRA’s part. Several events were mentioned. Review the Town Hall recording at the Learning Center for more, I cannot do it justice in print. Our PR and communications are in good hands.
Mr. Meadors noted that Legislative Bootcamp has been called a “money grab.” He stated NCRA does not make money on bootcamp and reiterated what an important program it really is.
Jocelynn Moore expounded on bootcamp, explaining that it is extremely immersive training on how to be effective grassroots lobbyists. She stated that the training is “going to give you all of the tools necessary to go in front of a legislator, oppose legislation that doesn’t agree with the profession, or advocate for a bill coming through. Some of the topics covered will be “politics 101,” how associations work, and how you can mobilize with other members in your state to move forward on a particular issue.
The Training for Realtime Writers Act was mentioned. It was also mentioned that it will be difficult to reintroduce this under a Congress attempting to cut spending. More information will be provided on that at bootcamp, but also more on the situation from Indiana. Participants will learn how to advocate in front of different parties and teach members to speak to legislators, because legislators do not always have all of the information we have about our field.
Ms. Moore continued on to talk about the Indiana issue. The proposed prohibition of stenographers from Indiana courts was revealed. We learned that NCRA began a grassroots campaign to find out what happened and why the proposed change was introduced. The organization has found difficulty getting information about the change, but finds the language to be discriminatory and mandatory, robbing judges of their discretion and forcing them not to use a stenographer.
It was a packed hour. My only criticism of the event would be that they ran out of time for questions. But you know what? It happens. President Meadors directed that efforts should be made to record questions asked and that efforts would be made to have them answered. Everything wrapped up with Dave Wenhold thanking the participants for coming out on a Saturday. He said that if you get any information on Indiana, you can pass it to him or Ms. Moore. President Meadors noted that just showing up and asking questions meant participants were dedicated to the profession. The meeting subsequently came to a close.
Refinement of the programs we have is going to seize the day here. Leadership is doing something very impressive. My opinion may not count for much, but I’d thank each of them for the hard work that they do and continuing to fight for this profession. It’s inspiring, and I hope reading a little about it has inspired all of you.
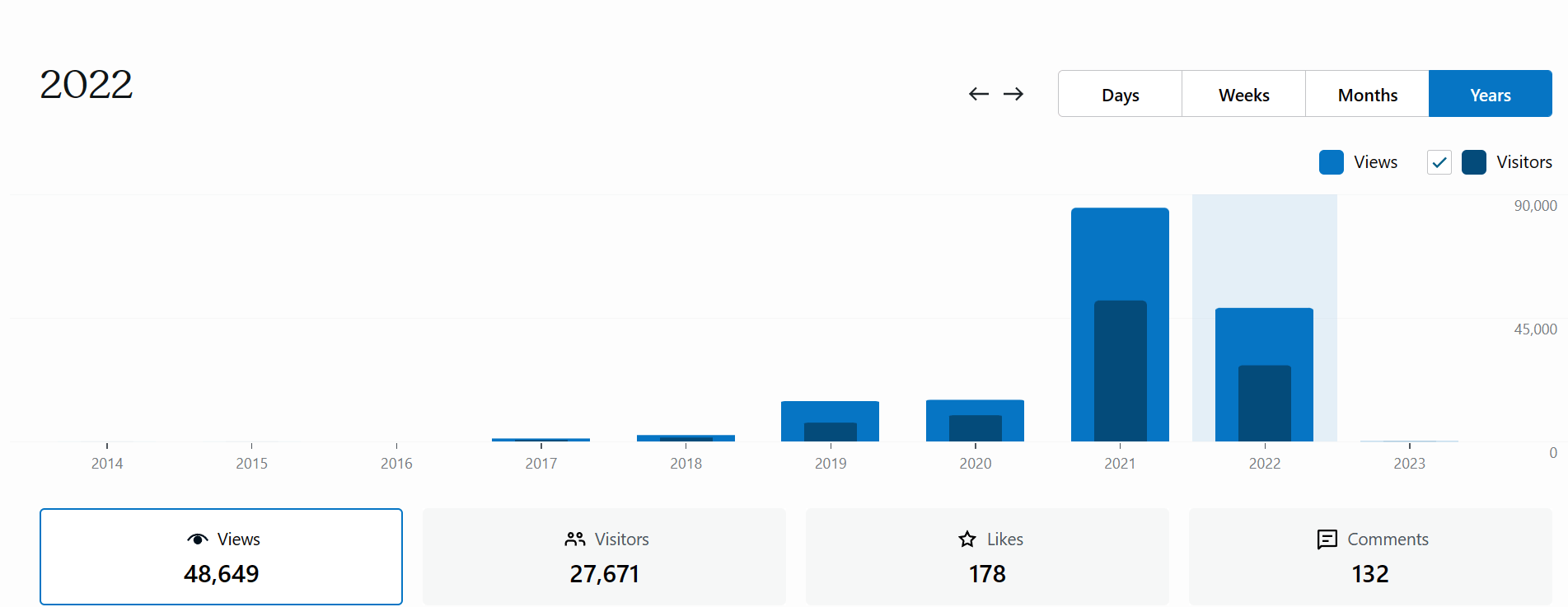
Happy New Year everyone! I wanted to provide a statistics update for the blog and some thoughts looking forward.
In 2022 there were 27,671 visitors and 48,649views. This is a drop from 2021’s 51,423 visitors and 85,117 views. It is, however, still a massive upgrade from 2020, which saw 9,526 visitors and 15,158 views. This is in the context of a field estimated to be about 30,000 members. This was expected because funding for the blog was not as high this year and the advertising I could run for steno or consumer awareness was limited.
Stenonymous.com 2022 visitor stats.
Due to the drop in funding, I’ve been forced to find low-cost ways to spread the message and get attention on our issues.
Christopher Day attracting attention to the stenographic legion and Stenonymous Q4 2022. Times Square.
Just kidding. While I was out there promoting Stenonymous, their protest was about the Burmese people, and while I don’t mean to co-opt their movement, I did want to make a point about the importance of my work as an independent body. Everybody has an angle. Big boxes want you working for them cheaply, manufacturers want to sell you stuff, I want people reading my work. The difference between me and a lot of other “influencers” is that my angle is not purely monetary. There is a social and political component to what I do. With your continued support, either through passing me information or monetarily, this movement to defend the interests of working reporters can only grow to have real teeth.
There are indications change is coming. Some of my sources have reported New York City copy sales as high as $1.00 per page and originals upwards of $4.30 per page. This is contrasted against the situation as it was in 2010 and many years thereafter, $0.25 copies and originals as low as $2.80. What’s happened in the last 5 years to make prices quadruple? Documentation and broadcasting of how bad New York freelance reporters are getting screwed. The documentation of events in our field has a value, but media growth will have more value. If we can get it in front of every law practitioner how easy it is to edit audio, they might be less inclined to charge into digital. If we can get it in front of jobseekers that digital court reporting doesn’t have the same career options as steno, they may find their way to steno or another career that treats them better. If we can continue to gather and release data that helps players in the market make informed decisions, it may reinvigorate an industry that some feel is in decline. If we can communicate to the public that the integrity of the appeal system is contingent on the accuracy of these records, we can get more people behind our cause.
Again, have a happy and healthy new year. I’ll be doing what I can to make this one count.
Christopher Day looking forward to the future of Stenonymous
There are a lot of great choices out there, like the shop that TCRA just opened or Steno Swag. As some of you probably saw in an unfortunate social media spam incident, I’m dipping into the world of stenographer merch.
The official Stenonymous.com merch launch post.
Tired of your old steno shirt?
Faking being tired of one of the best gifts I ever got.
Try something new!
Christopher Day, Stenonymous.com merch launch
Some of the designs are an in-your-face style, but there’s a little something for everyone.
The images are also available to download. If you have your own little side hustle, feel free to buy the image as your license to slap it on whatever merch you want.
Some time ago I wrote about how a quote was falsely attributed to the National Court Reporters Association, stating there’s a need for 33,000digital court reporters by 2033. That misquote was still up in the first quarter of 2022, and I brought it up in a discussion with President Dibble. Upon checking again today, I found the quote removed. This is a win for the profession. Student consumers across the country looking into court reporting don’t deserve to be misled.
In other news, the Illinois Court Reporter Association published a document on their recent lobbying victory.
This shows the importance of reporters coming together and working for things that collectively benefit us. State and national association membership is one of simplest ways to organize and act. A big thank you to both associations for showing us that.
I have more to write on NCRA, but I need time to collect my thoughts in light of this new information. Enjoy the victory, stenographers!