There are two ways to handle the November 4 STTI podcast with Anir Dutta, president of Stenograph. I can go point-by-point and try to poke at every little gripe I have, or I can go “big picture,” give people a rough outline, and let people decide for themselves. But first, let me just point out how obvious it is that STTI is a digital court reporting marketing tool. It’s November 2021, they’ve been around for two years, and they have one podcast. Now let’s compare that to a real field. Anna Mar’s Steno Talk first launched in March and is already on Season 2. Shaunise Day’s Confessions of a Stenographer also has done about 30x the content in the time it’s taken STTI to do one. It seems very strange that the “declining, shifting” industry has so much more content. Maybe there’s a lot more to talk about in an actual industry with actual news.
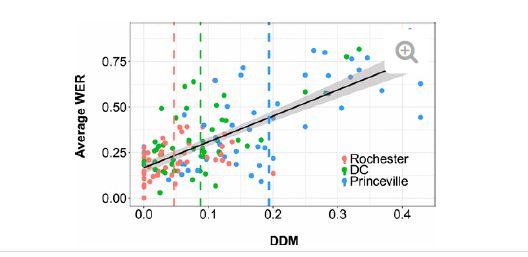
Now let’s do some big picture work. Artificial intelligence, AI, in its current form, is easy to understand. In brief, programmers use a recipe or instructions called an algorithm to tell a computer what to do. The computer is then fed lots of data. In automatic speech recognition, this data might be people speaking paired with accurate or semi-accurate transcriptions. Simply put, the algorithm tells the computer to go through the data and make future decisions based on patterns. Luckily for us stenographers, real life does not adhere to perfect patterns. Investors and companies that trust computers to make them money off of AI have a big chance of failure. Gartner predicted that 85% of AI business solutions would fail by 2022. We now have a real-life example of this. Zillow was using algorithms to predict the housing market. The value (market capitalization) of Zillow’s shares just plummeted $35 billion. Automatic speech recognition, ASR, which is AI for “hearing” and “transcribing” speech, has much larger companies than Zillow working on it. IBM is one of those companies, and for comparison, their market capitalization is, as of writing, about $103 billion. In a 2020 study of IBM, Apple, Google, Microsoft, and Amazon, companies with a combined market capitalization (value) of $8.873 trillion, the ASR was 25% to 80% accurate depending on who was speaking. My argument? If these behemoths haven’t figured this out, nobody else is close.
What is Stenograph’s answer to that? They mention in the podcast that they created the engine that their automatic speech recognition is running off of. This is meant to assure the listener that though there is clear science and data that suggests there’s no chance in hell Stenograph’s automatic speech recognition is better than anyone else’s, you should just try it, because there’s no risk to you — you only pay for it if you use it. They know that if they can get you to try it, some of you will experience post-purchase rationalization and keep using it even if it’s not very good. We, as consumers, need to be honest with ourselves. ASR is open source. Anyone can play around with it for free, customize it, and sell their version of it. Whatever Stenograph’s amazing programmers have cooked up is much more likely to be a tweaking or reworking of what is already available than a bona fide original work.
The podcast supports my assertion. It’s heavily laden with corporate propaganda techniques. Some common propaganda examples used generally in tech sales:
- Fear appeals: Keep up with the technology or get left behind! Buy! Buy! Buy! OR ELSE.
- Bandwagon: If you’re not paying for support, you’re not supporting the profession. EVERYONE must have this.
- Name-calling: You don’t like TECHNOLOGY? Luddite! YOUR PROFESSION WILL GO THE WAY OF THE HORSE AND BUGGY, HAHAHA.
- Card stacking: Our product is new, and wonderful, and we’ve put a lot of time and effort into it. But we are going to forget to mention that it would hurt minority speakers and allow large private equity companies to offshore your jobs with impunity.
- Glittering generalities: Think buzzwords. Increase in productivity. Custom-built engine. If you don’t know exactly what something means, the salesperson does not want you to question it.
- Transference: This takes someone’s good feelings about something and tries to transfer it to the company or product. Anir did this during the podcast when he said in the future technology will be “democratized.” We live in a republic that loves the concept of democracy. This is so powerful that when I heard Anir say it, I felt good. Good feelings make it harder to remember the bad things people do to us. It’s not really that different from any abusive relationship, it’s just a business relationship.
- Ad nauseam: Repeat the same message over and over. If no one stands in your way, it becomes truth. For example, did you know technology is getting better every day? I guess someone forgot to tell that to whatever technology powers Stenograph customer service. Or perhaps technology is not getting better every day and that is a story we are sold ad nauseam.
I do not believe these things to be inherently evil or wrong. A sale is a sale. But when salespeople are used as instruments of ignorance, the wielder has gone too far.
On the topic of tools, some have pointed to our field’s adoption of audio sync and how that was widely hated and is now ubiquitous. Let me go on record and say audio sync hurt our field. Agencies started telling my generation of reporters “don’t interrupt, just let the audio catch it.” We trained an entire generation to sit there like potted plants while testimony was lost. No wonder so many from my generation left the field. They never developed the crucial skill of communicating our need to get every word. Dealing with the very simple skill of asking for a repeat became a harrowing and dreadful experience. More than that, audio sync kills productivity. In a dense layout, my transcription time is somewhere in the ballpark of 20 pages an hour. I used to use audio sync, and on a bad day, my transcription time was probably half that. I doubled my productivity by completely rejecting the “new” technology. I don’t disparage people that use audio sync, it’s a tool in our arsenal. Almost every reporter I know uses it to some degree. But beyond our post-purchase rationalization of “it is a wonderful tool for us,” I have not seen empirical evidence or reliable data that suggests it improved productivity or profit. It made us feel better because we could let some stuff go, and now it’s being weaponized to say “see, that worked out okay! This will too!”
On or about November 2, 2021, I wrote to Anir Dutta via snail mail. A copy will be downloadable below. I was very honest about my intentions. Stenograph had a chance to stop the boycott and didn’t even try.
Maybe its trainers should sue the company for the lost income experienced during the boycott. There’s federal law against false advertising in 15 USC Section 1125. Seems to me that by continuing to press the ASR to consumers against available data and evidence, Stenograph has set itself and its independent trainers up for a massive loss. Stenograph is also potentially cutting into the earnings of its customers by pushing its ASR as a productivity booster when it may very well turn out to be a productivity killer. So if the company continues down this path and finds itself facing lawsuits, you read it here first.
Just to drive home my point about tech sales, I created a computer program that produces thousands of transcript pages a minute. The program code and a sample transcript are available for download.
Then I announced to the world that my brand new program could do transcripts faster than every stenographer in the country. None of you can disprove that. It’s true.
Tell your clients $1 per transcript. This is the situation we are all living together. Caveat emptor.