I’ve written extensively about AI and ASR, and in particular how ASR could cause further delays in court record production. I’m sure entering the terms AI or ASR into the search box at Stenonymous.com will reveal plenty of the opinions and facts I’ve recorded over the years.
Truth be told, though, with clean enough audio, it’s also my firm belief that ASR can work the other way, producing a usable first draft of a court transcript. Sorry, but, from what I’ve seen, this is likely true. The catch is that, short of having a professional tech onboard to make sure the audio is coming in clean, you often won’t have the cleanest audio in depositions and courtrooms even under the best circumstances with fully willing participants.
I’d like to take a moment to acknowledge the prevalent form of AI today, the LLM or generative chatbot or whatever you want to call it. When I was a kid, the closest thing we had to it was SmarterChild. Now there’s ChatGPT, Grok, etc.
And they have no problem killing people, because in America’s rush to see what this technology can do, we didn’t bother to put effective guardrails on the damn things.
Now, I’ll be the first to admit that there are great use cases for these glorified chatbots. They can give pretty accurate information. Like when I asked Grok what Stenonymous.com is.
Grok’s response to “What is Stenonymous.com?”
But again, I’d like to take the time to mention that there will be casualties. These chatbots, for better or worse, tend to validate the feelings of the user. For the mentally ill, they can validate and enhance delusions. For the young, as we’ve seen, they can encourage suicide.
I am but one voice. But I say legislate. We need legislative guardrails on this technology. We need legislators to stop looking away from what they don’t understand and start understanding that the world is different now and the needs of society are great. Technology must be kept up with by lawmakers.
But I have very little hope. I’ve seen the executive branch fail at fighting the most obvious and documented corporate fraud, right up until the executive branch became enslaved to wealthy interests through The New Emperor. The Supreme Court is enslaved to wealthy interests through open bribery. The Congress is enslaved to wealthy interests through the Citizens United ruling. We have very serious problems in America.
At the end of the day, I can only hope that you’re doing as well as me, reader. Or better. I’ll continue to use my voice.
But for now a moment of silence for all the unsung victims of AI.
Ai-Media acquired Alternative Communication Services in May 2020. According to the recollection of one source, there was a little buzz about it at the time and there were some who were concerned about the replacement of captioning providers and some that didn’t believe such a thing would happen. Well, they’ve been touting something called LEXI 3.0.
“…uses the power of AI to deliver results rivaling human captions, at a fraction of the cost.” – Ai-Media“Sad to see this. Rivalling human captioners? You have (or had) an amazing team there — please don’t sell them short in the name of profit.” – Mike Rowell, RDR
This wasn’t the only post done on the matter.
“…AI to deliver results rivalling human captions, at a fraction of the cost.” – Ai-Media
So, I guess I really have to say to captioners what I have said to court reporters. If I get some funding behind me there’s a lot we can do. We could sponsor independent studies into the accuracy of AI versus human transcribers/captioners. What we have so far in that department is promising.
But even short of that level of funding, we could do more advertising to increase public awareness about misleading technology claims and perceptions, something that is hitting mainstream media right now. After all, as I reported on this blog, Microsoft said they had achieved tech as good as human transcribers back in 2016. Then it flopped in the Racial Disparities in Automatic Speech Recognition 2020 study. Verbit flip-flopped between its series A and series B funding, first talking about saving on manual labor and then saying that they would not take the human transcriber out. So now when Ai-Media claims its LEXI 3.0 is rivaling human transcribers, it makes me wonder if this might be just another claim that they’re using to sell, sell, sell.
The best part? They don’t even have to lie to mislead. Check out the post above. “The world’s most advanced and accurate automatic captioning solution!” This is what’s referred to in legal circles as puffery. Even if it’s BS, it’s probably not false advertising. “Watch our video to see how LEXI 3.0 uses the power of AI to deliver results rivalling human captions, at a fraction of the cost.” Well, anybody can declare something rivals something. I declare apples rival oranges and Stenonymous rivals Veritext. It doesn’t mean anything. At the end of the day, if the AI gets 40% and captioners get 90%, they still rival each other, it’s just that one would be a really poor rival. At a fraction of the cost? Does that mean all of the cost savings are passed directly to consumers? It sure isn’t a guarantee.
This is why I’m so forward about educating reporters on marketing tricks and propaganda techniques. We are all subjected to media that influences our thoughts, and those thoughts go on to influence our actions. If a person is constantly inundated with the message that technology is exponentially growing and that it’s coming for all the jobs, they won’t seek out information that challenges that belief, like all the links I posted above that most people probably skip over out. Thanks confirmation bias and busy schedules.
Meanwhile, there’s a totally alternate reality where we start dumping money into calling out these companies and working out exactly how true their claims are so that we can share it with the world.
How court reporting companies are getting away with charging top-shelf prices for undervalued work…
The overpriced court reporter page is something that comes up occasionally in legal circles. All through my early career, law firm owners I worked with mentioned how their firms were stuck with expensive court reporter bills. As a young stenographic court reporter, I was paid very little, and later learned that court reporters in my city were about 30 years behind inflation. This set me down a path of skepticism when it came to what court reporters are told about themselves, their industry, and the public’s perception of them. How could lawyers be paying so much when I was making so little and such a large part of the transcript creation was on me?
Years later, as it turned out, some of the largest court reporting companies would get together using a nonprofit called the Speech-to-Text Institute (STTI). That nonprofit would go on to mislead consumers about the stenographer shortage to artificially increase demand for digital court reporting. Tellingly, while a U.S. Legal Support representative had no problem using the word “libel” on one of the female members of my profession, USL and the other multimillion dollar corporations never dared utter a word about my eventual fraud allegations. The companies wanted to trick consumers into believing stenographers were unavailable due to shortage and force digital court reporting on them, where matters are recorded and transcribed.
This set off alarm bells in the world of court reporting. Stenotype manufacturing giant, Stenograph, also represented in STTI’s leadership, shifted from supporting realtime stenographic reporters to shoddy service, and began to call its MAXScribe technology realtime. Realtime, as many attorneys know, is a highly trained subset of court reporting that often comes with a premium. These bait-and-switch tactics on the digital court reporter side of the industry caused a nonprofit called Protect Your Record Project to spring up and begin educating attorneys on what was happening in our field. But as of today, the nonprofit has not reached a level of funding that would allow it to advertise these issues on a national scale — this blog’s in the same boat.
So as more of the workforce is switched to digital reporters / recorders and transcribers, we’re seeing companies use influencers and other media to lure transcribers in for low pay. In short, digital court reporting is now synonymous with side hustle. These companies are going to take the field of skilled reporters that law firms and courts know and love, replace them with transcribers, and go on charging the same money. For the stenographer shortage, these folks were dead silent for the better part of a decade. Now that they need transcribers to replace us, they’re going all out to recruit.
Shopify talks about transcribing as a side hustle.Shopify talks about transcribing as a side hustle.
“What do I care?” That’s what a lot of lawyers and paralegals might be asking at this point. Well, I may not write as well as Alex Su, but I’ll do my best here. First, there are egalitarian concerns. In the Testifying While Black study, stenographers only scored 80% accuracy on the African American Vernacular English dialect. This was widely reported in the media, but what was lost by the media was the reveal of pilot study 1, which showed everyday people only transcribe with an accuracy of about 40% (e226). When we’re talking about replacing court reporters with “side hustle technology,” we’re talking about a potential 50% drop in accuracy and a reduction in court record quality for minority speakers, something courts are largely unaware of. According to the Racial Disparities in Automatic Speech Recognition study, automation isn’t coming to save us either. Voice writing is the best bet for the futurists, and it’s being completely ignored by these big companies.
There are also security concerns. When we’re talking about utilizing transcribers, we’re talking about people that have an economic incentive to sell any private data they might gain from the audio or transcript. If transcription is outsourced, a bribe as low as $600 might be enough to get people acting unethically. Digital court reporting companies have already shown they’re not protective of people’s data — in fact, companies represented in the Speech-to-Text Institute. This also leads to questions about remedies for suspected omissions or tampering. Would you rather subpoena one local stenographer or teams of transcribers, some possibly outside of the jurisdiction?
Finally, there’s an efficiency issue with digital court reporting. Turnaround times can be much slower. Self-reported, it can take up to 6 hours to transcribe 1 hour of audio. By comparison, 1 hour of proceedings can take a qualified stenographer 1 to 2 hours to transcribe. That’s 3 to 6 times faster. Everyone here knows stenographers aren’t perfect and that backlogs happen. Now imagine a world where the backlog is 3 to 6 times what it is today. In one case, a transcript took about two months to deliver. If we’re going to hire teams of transcribers to do the work of one stenographic court reporter, aren’t we going backwards?
Consumers are the ones with the power here. They can demand stenographers, utilize companies that aren’t economically incentivized to lie to them, and spread awareness to other consumers. Consumers, lawyers and court administrators, decide the future. Knowing what you do now, do you want a court reporter or a side hustler at your next deposition or criminal case?
—————————-
Written by Christopher Day, a stenographic court reporter in New York City that has been serving the legal community since 2010. He is also a former board member of the New York State Court Reporters Association and a former volunteer for the National Court Reporters Association STRONG Committee. Day also authors the Stenonymous blog, the industry’s leading independent publication on court reporting media, information, data, analyses, satire, and archiving of current events. He also appeared on VICE with regard to the Testifying While Black study and fiercely advocated for more linguistics training for court reporters in and around New York State.
Donations for the blog will help run advertising for this article and others like it, as well as pay for more journalists and investigators. If you would like to donate, you may use the donation box on the front page of Stenonymous.com, PayPal or Zelle ChristopherDay227@gmail.com, or Venmo @Stenonymous. Growing honest media to combat misconceptions in and about our marketplace is the premier path to a stronger profession and ultimately better service to the legal community.
A posse ad esse.
Addendum:
By sheer coincidence, an article on the side hustle was released the same day as my post. NCRA STRONG’s Lisa Migliore Black and Kim Falgiani really hit it out of the park with this one. Apparently FTR and Rev say they have security in place to prevent sensitive data from being shared. But FTR is known for selling “deficit products,” and Rev is known for its massive security breach. So check out the article by Chelsea Simeon linked above and enjoy!
With a wave of recent tech layoffs, it seems unlikely the tech giants will have a massive tech breakthrough. They’re preparing for tough times, which signals to me they’re probably not expecting anything revolutionary. According to some sources, as many as 73,000 tech workers have been laid off this year.
As reported by Fortune and Kevin Kelleher, Deloitte has released a report. A survey of 2,620 executives in 13 countries found 94% of respondents considered AI critical to success in the coming five years. Yet only about 50% of solutions were considered high achieving, leaving about 50% of solutions low achieving.
The article does state that global spending on AI is set to nearly double from $33 billion in 2021 to $64 billion in 2025, but this does not seem to comport with the dropping interest in AI investment reported. Only 76% of respondents plan to boost AI investments, down from 85% a year ago. As I see it, there are two possible futures. Either executives will take a step back and realize that somewhere between half and 80% of these projects are not working out, or they’ll continue down the path of burning money on what’s essentially a hand of blackjack with a nice side bet. For those that don’t gamble, that’s “okay odds of winning something with a very small chance of making a lot of money.”
Of course, this is all about AI generally. Automatic speech recognition (ASR) or natural language processing (NLP) is the subset of AI that deals with or theoretically threatens our profession, and if regular AI solutions are not working out, something as complex as ASR doesn’t seem like it’ll be perfected any time soon.
We are in a bad time for factual information. Some sources claim 15 to 30% of market research data is fraudulent. I can’t help but wonder if the ballooning estimates on market size for AI and ASR are wishful thinking put out there to get investors and decision makers to part with their money and avoid another AI winter. After all, it looks attractive to say speech recognition will grow from $11 billion in 2022 to $49 billion in 2029, and it looks attractive to say the AI market will grow to $1.3 trillion by 2029. “Buy in now!” But if half the solutions are low achieving, aren’t they throwing half of that trillion in the trash? And isn’t it a little odd to forecast that an industry will miraculously grow from $64 billion in 2025 to $1.3 trillion in 2029? Some of the fastest-growing industries are around 12% growth. Meanwhile they’re talking about something like 500% growth every year for 4 years. I know jobs don’t necessarily relate to revenue/profit, and I accept these figures are from different sources and therefore may be calculated differently, but how is such explosive growth expected to take place without adding jobs? Were the thousands of workers just laid off not contributing to the growth? Would the growth not slow with such future uncertainty? The AI industry is set for 500% growth but the world GDP is something like 10% growth in a great year?
This also calls into question the market research and data in our field. Will our “sten tech” companies’ AI ventures be successful? Could numbers be played with to get court reporting consumers to buy into new tech ideas? Could the numbers be played with to make court reporting firms more attractive to private equity buyers? I’m already certain they’re being played with to sell digital court reporting.
Christopher Day’s remarks on the data in the court reporting and stenotype services field.
I will continue to document the stats. Let this serve as a reminder that we need to be careful what stats we accept in our minds as true and always be open to new information. As always, I invite readers to share comments, contrary ideas, or even correct me. What do you think?
Some have seen this video. I got around to it. I have honest reservations about giving someone like him more press and attention, but then, my audience outnumbers him by a lot, so if you all have the data, it’s a force multiplier and family he doesn’t have. You can tell Readback is terrified of us because they don’t have the guts to leave the comments on and get called out on their lies. Let’s take advantage of their fear.
He likens court reporting to medical transcription. I made a short TikTok on that. I’ve spoken to Mitch Li from Take Medicine Back. Emergency room physicians are being pushed out for nurse practitioners in the same way big money is trying to push us out for digital. Guess what? The doctors largely don’t like that their scribes were pushed out, and the quality of medical transcription has been suffering because of its lean to automation. As a matter of fact, as a young reporter, I was getting requests to get involved with medical transcription (MT). That was only ten years ago. Nowadays the Association for Health Documentation Integrity says there’s a transcriber shortage.
Wow, sounds like the exact excuse they’ll use in court reporting.
It’s so bad that they STILL want to attract court reporters to do medical transcription. So how good was automation for MT anyway?
“Automation is so wonderful, please God send the court reporters to save us.”
Well, isn’t it interesting that jerks like no-steno man (NSM) created problems in an industry that they didn’t bother to stick around and solve? “Oh, people are dying from the reckless automation of something important? Exit stage left. Time to try court reporting!” Guess what? We’re not medical transcriptionists, and we’re not letting you destroy our industry without a fight, you jackalope.
Ultimately, I decided to eviscerate your puffery with cold, hard, facts.
His entire line about automating medical transcription and making it cheaper is fluff. What good is cheap, useless, garbage? And make no mistake that automatic speech recognition, natural language processing, artificial intelligence, or whatever fancy label we want to put on it, is just that. The objective science that exists today says that it’s 25 to 80% accurate from all the major players. When was the last time you had a 20% untran and called yourself “neartime?” This also kills his argument about the technology being revolutionary. He’s comparing our 99% real-world accuracy rating to AI’s 80-at-best average accuracy and calling it revolutionary. This is more like if Google maps led you the wrong way down a one-way street about 20% of the time. It’s not acceptable and we shouldn’t be forced to pretend that it is. If they’re not using full automation, they’re using human transcribers, and that means there are zero efficiency gains from a manpower perspective. This is a hide-the-ball trick of saying technology is better than it actually is to fool investors and consumers. It only fools people who have not seen the trick before.
Next strawman argument by the liar: Court reporting costs have gone up. In actuality, we’re working for less than we were 30 years ago adjusted for inflation. Let’s call this out for what it is, a ploy to get court reporters scared of demanding the rates and pay that they deserve. Less money in our wallets means less money for us to spend on our associations to fight for us. The push to get court reporters to accept less has been largely successful in the last decade, and it has been driven by low-intelligence businesspeople that look at the labor expense as something to be cut no matter who it hurts. There are over a million lawyers in the United States and about 30,000 of us. We’re a rare commodity and need to start acting like it — keeping pricing reasonable, but not abusively low.
Notably, NSM refers to the democratization of technology and talks a good game about how realtime is too expensive for the little guys to afford. Anir Dutta of Stenograph also referred to the democratization of technology in the Speech-to-Text Institute podcast. What does this tell us? This is a coordinated buzzword in whatever business circle they’re all playing in. They’re using democracy as transfer propaganda. Who doesn’t like the sound of democratization in a free society like the United States? This ignores that in actuality adopting his active reporting model would likely hurt democracy in the form of disproportionately hurting the quality of black and minority speakers’ records. We have put immense effort into ensuring everyone has an equal record. Are we willing, as a field, to allow technological snake oil to kill the equality we stand for every day in every proceeding?
The puffery in the advertising is on full display:
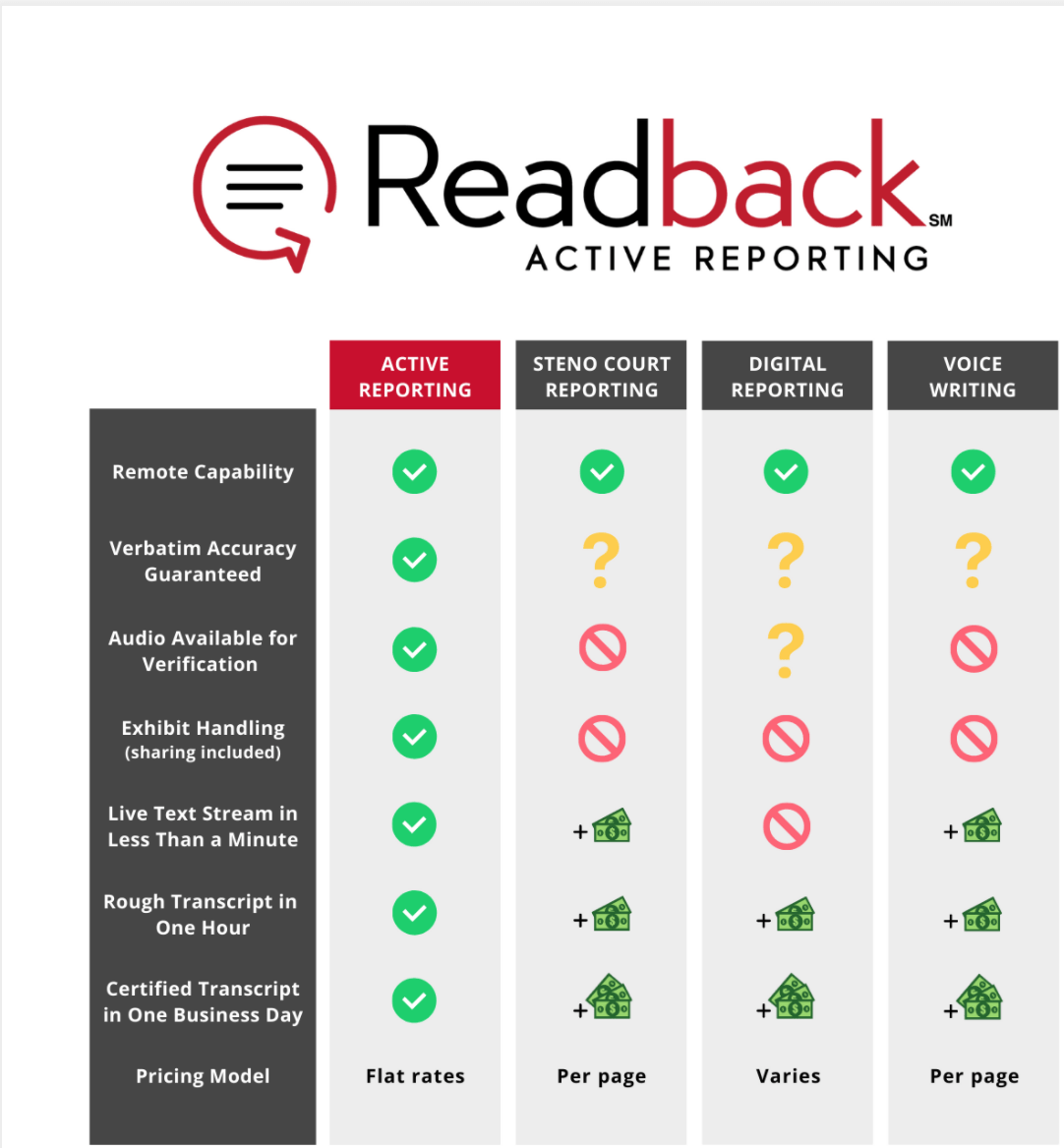
Active Readback gets several things wrong in their advertising.
This looks intimidating to a stenographic court reporter that doesn’t grill it a bit. First, questioning our accuracy. How dare they? I just gave the science. They’re not guaranteed accuracy. Nobody can guarantee accuracy. What happens if a word is wrong? Does everyone get the service for free? That would be a guarantee. Tellingly, they make no such promise. Audio available? Stenographers have been using audio for years. It’s called asking nicely or getting a subpoena. Lawyers don’t want to re-listen to depositions anyway, that’s why they hire us. Exhibit handling, stenographers literally led the way and trained clients on that after COVID. The rest of it, hey, we can give all that away for free too, but we like our businesses to be profitable instead of losing $13 million a year like VIQ Solutions. We need profitable businesses so that we can continue to provide the same great service we have for over half a century. NSM’s investors must have their mouths agape. He’s not charging what the market can bear, and that’s a recipe for low returns and disaster in business. I’m pretty sure I learned that in business 101. What’s this guy’s excuse?
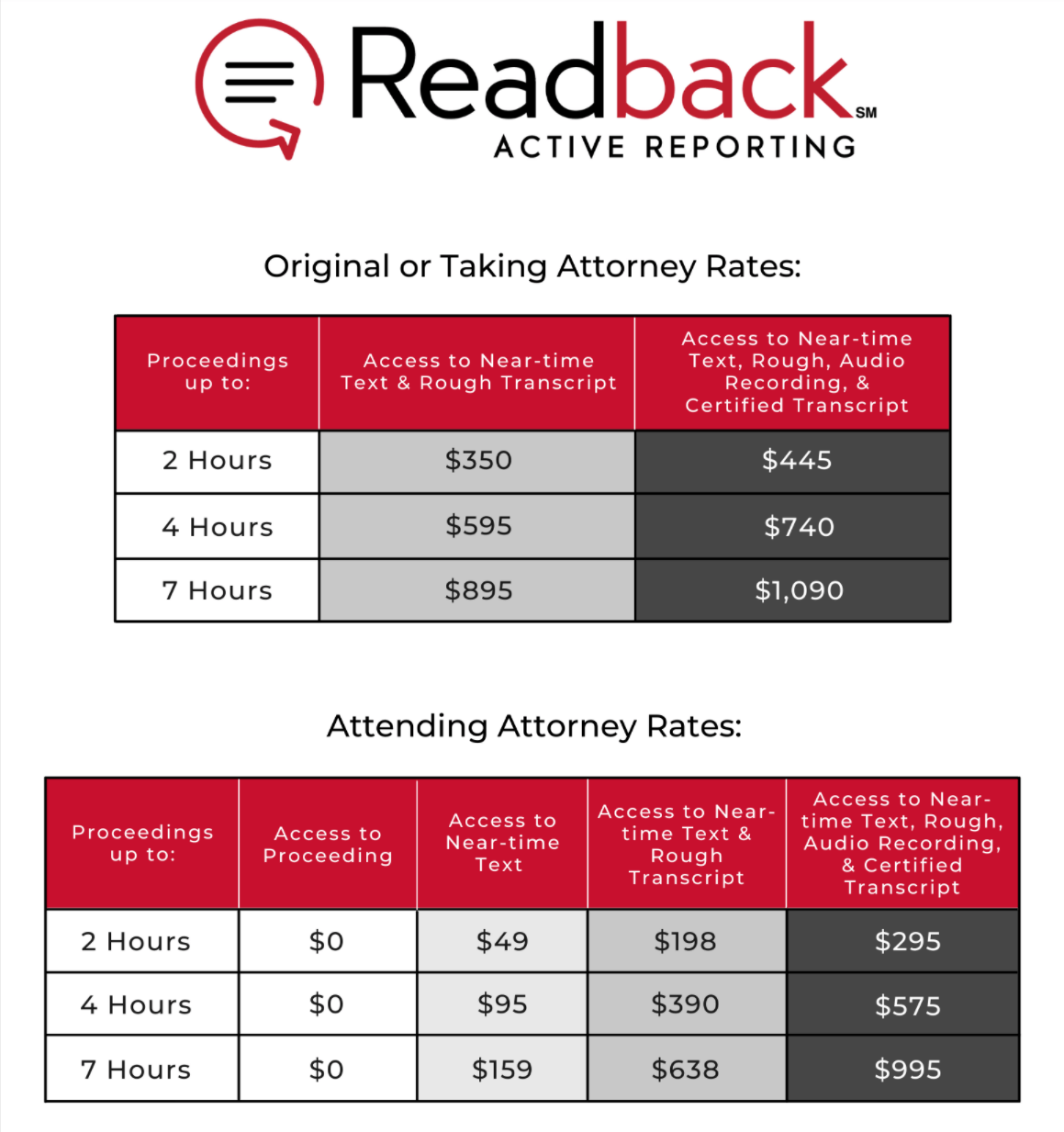
The low, flat rate that he talks about in the presentation isn’t really that low, which tells me that this process isn’t automated. Just to break it down, there are stenographers working for less than $4 per page in New York City right now. Assuming 60 pages an hour, that’s $480 for two hours. Lawyers can get the tried and tested stenography for a little bit more than the brand new maybe-this-works-maybe-it-doesn’t Active BS. This isn’t a sell, it’s an embarrassment.
“Active Readback, charging 72% of what a stenographer charges for half the quality, guaranteed.” (Parody)
Final point I’ll address is his mention about the shortage and how the stenotype is “hard on its operators.” We’ve been cremating our shortage despite some of the biggest names in the business, Veritext and US Legal Support, actively sabotaging us. Additionally, our technology is a lot easier on the hands than the Mechanical Turk game that Active and others are probably playing. Mechanical Turk lets services crowdsource transcribers. When people buy into active reporting, they’re likely buying into inefficiency and hurting workers.
Stenographers, I cannot stress this enough: Hold your ground. Our industry is worth $3 billion and we control most of that. The people that are trying to convince you to give up and run away are not doing so out of the kindness of their heart. These are liars, nothing more. Now that I’ve peeled back the curtain and exposed some of the flaws, I hope you will follow the Protect Your Record Project motto of “connect, educate, advocate.” I hope you will follow the STRONG motto of “we are strongest together.” I hope that if you found this blog post helpful, you will take the time to donate below.
I also hope that Active Readback will come on here and comment. We do not cower behind censorship like them. Perhaps that is all the world needs to see to know whose version of events is truest.
The more money I make from my media, the harder I can fight.
Stenograph has been in hot water because of its degradation of quality and service. This led to a boycott of the company by stenographers across the country, a boycott which continues to this day. As stated in my Oh My update, Stenograph’s push into automatic speech recognition is not being done properly. It’s being sold as a productivity boost, but available science says AI/ASR is a productivity killer. Anir Dutta, Stenograph’s embattled president, doesn’t care. He ignored a personal letter from me alerting him to these issues.
As if these issues were not enough, Stenograph promised to meet with Texas Court Reporters Association members and address their concerns. The company then retracted its agreement and set up its own meeting, likely to confuse consumers and attempt to manipulate us. TCRA addressed Stenograph’s behavior as follows:
Stenograph claims its plan is to meet with TCRA members.Stenograph apparently pulls out because one member they don’t like might be in attendance.Sonia G. Trevino, TCRA President.
Then, perhaps under the delusion that stenographers are stupid, Stenograph decided to hold its own meeting:
Stenograph attempts to create its own meeting in place of the Texas Court Reporters Association town hall.
This is a bait and switch. This behavior is disgusting and in my opinion we shouldn’t condone it as a field. It’s very clear what’s happening. Stenograph does not have an answer for why it is requiring stenographers to get releases for data it wants to steal from us or the liability it wants to be put on us, as per its licensing agreement:
“You understand you are responsible for obtaining consents and authorizations for data we may or may not be using.” – Stenograph (parody)“We may be using your data to build our digital reporting products, but you’re not entitled to anything from it, which we’ve just unilaterally decided.” – Stenograph (parody)
Since Stenograph doesn’t have an answer, it doesn’t want to be in a position where that’s revealed. Again, I know factually that there are great people that work for the company and great software trainers for the software. That does not excuse what they’re doing. They’re barreling into automatic speech recognition in a haphazard, might-makes-right, and manipulative way that should give us all pause. We are the profession of blatant honesty. You say it, we write it. Can we not agree that this is not a direction we want a company, one that is practically our namesake, to take?
I have a message for Anir Dutta and Stenograph: We may not be computer programmers or $10 million companies, but human intelligence is not linear, it’s on a bell curve. We are not “stupid scribes” for you to play word games with. Words are all we know. We listen to people for a living, and we know when we’re hearing lies. If you have deluded yourselves into believing that you are so far ahead of all of us on the curve that you can lie to us with impunity, then I offer you the same stenographic proverb I offered Naegeli. TKPWHRUBG.
There are two ways to handle the November 4 STTI podcast with Anir Dutta, president of Stenograph. I can go point-by-point and try to poke at every little gripe I have, or I can go “big picture,” give people a rough outline, and let people decide for themselves. But first, let me just point out how obvious it is that STTI is a digital court reporting marketing tool. It’s November 2021, they’ve been around for two years, and they have one podcast. Now let’s compare that to a real field. Anna Mar’s Steno Talk first launched in March and is already on Season 2. Shaunise Day’s Confessions of a Stenographer also has done about 30x the content in the time it’s taken STTI to do one. It seems very strange that the “declining, shifting” industry has so much more content. Maybe there’s a lot more to talk about in an actual industry with actual news.
Now let’s do some big picture work. Artificial intelligence, AI, in its current form, is easy to understand. In brief, programmers use a recipe or instructions called an algorithm to tell a computer what to do. The computer is then fed lots of data. In automatic speech recognition, this data might be people speaking paired with accurate or semi-accurate transcriptions. Simply put, the algorithm tells the computer to go through the data and make future decisions based on patterns. Luckily for us stenographers, real life does not adhere to perfect patterns. Investors and companies that trust computers to make them money off of AI have a big chance of failure. Gartner predicted that 85% of AI business solutions would fail by 2022. We now have a real-life example of this. Zillow was using algorithms to predict the housing market. The value (market capitalization) of Zillow’s shares just plummeted $35 billion. Automatic speech recognition, ASR, which is AI for “hearing” and “transcribing” speech, has much larger companies than Zillow working on it. IBM is one of those companies, and for comparison, their market capitalization is, as of writing, about $103 billion. In a 2020 study of IBM, Apple, Google, Microsoft, and Amazon, companies with a combined market capitalization (value) of $8.873 trillion, the ASR was 25% to 80% accurate depending on who was speaking. My argument? If these behemoths haven’t figured this out, nobody else is close.
What is Stenograph’s answer to that? They mention in the podcast that they created the engine that their automatic speech recognition is running off of. This is meant to assure the listener that though there is clear science and data that suggests there’s no chance in hell Stenograph’s automatic speech recognition is better than anyone else’s, you should just try it, because there’s no risk to you — you only pay for it if you use it. They know that if they can get you to try it, some of you will experience post-purchase rationalization and keep using it even if it’s not very good. We, as consumers, need to be honest with ourselves. ASR is open source. Anyone can play around with it for free, customize it, and sell their version of it. Whatever Stenograph’s amazing programmers have cooked up is much more likely to be a tweaking or reworking of what is already available than a bona fide original work.
The podcast supports my assertion. It’s heavily laden with corporate propaganda techniques. Some common propaganda examples used generally in tech sales:
Fear appeals: Keep up with the technology or get left behind! Buy! Buy! Buy! OR ELSE.
Bandwagon: If you’re not paying for support, you’re not supporting the profession. EVERYONE must have this.
Name-calling: You don’t like TECHNOLOGY? Luddite! YOUR PROFESSION WILL GO THE WAY OF THE HORSE AND BUGGY, HAHAHA.
Card stacking: Our product is new, and wonderful, and we’ve put a lot of time and effort into it. But we are going to forget to mention that it would hurt minority speakers and allow large private equity companies to offshore your jobs with impunity.
Glittering generalities: Think buzzwords. Increase in productivity. Custom-built engine. If you don’t know exactly what something means, the salesperson does not want you to question it.
Transference: This takes someone’s good feelings about something and tries to transfer it to the company or product. Anir did this during the podcast when he said in the future technology will be “democratized.” We live in a republic that loves the concept of democracy. This is so powerful that when I heard Anir say it, I felt good. Good feelings make it harder to remember the bad things people do to us. It’s not really that different from any abusive relationship, it’s just a business relationship.
I do not believe these things to be inherently evil or wrong. A sale is a sale. But when salespeople are used as instruments of ignorance, the wielder has gone too far.
On the topic of tools, some have pointed to our field’s adoption of audio sync and how that was widely hated and is now ubiquitous. Let me go on record and say audio sync hurt our field. Agencies started telling my generation of reporters “don’t interrupt, just let the audio catch it.” We trained an entire generation to sit there like potted plants while testimony was lost. No wonder so many from my generation left the field. They never developed the crucial skill of communicating our need to get every word. Dealing with the very simple skill of asking for a repeat became a harrowing and dreadful experience. More than that, audio sync kills productivity. In a dense layout, my transcription time is somewhere in the ballpark of 20 pages an hour. I used to use audio sync, and on a bad day, my transcription time was probably half that. I doubled my productivity by completely rejecting the “new” technology. I don’t disparage people that use audio sync, it’s a tool in our arsenal. Almost every reporter I know uses it to some degree. But beyond our post-purchase rationalization of “it is a wonderful tool for us,” I have not seen empirical evidence or reliable data that suggests it improved productivity or profit. It made us feel better because we could let some stuff go, and now it’s being weaponized to say “see, that worked out okay! This will too!”
On or about November 2, 2021, I wrote to Anir Dutta via snail mail. A copy will be downloadable below. I was very honest about my intentions. Stenograph had a chance to stop the boycott and didn’t even try.
Maybe its trainers should sue the company for the lost income experienced during the boycott. There’s federal law against false advertising in 15 USC Section 1125. Seems to me that by continuing to press the ASR to consumers against available data and evidence, Stenograph has set itself and its independent trainers up for a massive loss. Stenograph is also potentially cutting into the earnings of its customers by pushing its ASR as a productivity booster when it may very well turn out to be a productivity killer. So if the company continues down this path and finds itself facing lawsuits, you read it here first.
Just to drive home my point about tech sales, I created a computer program that produces thousands of transcript pages a minute. The program code and a sample transcript are available for download.
Then I announced to the world that my brand new program could do transcripts faster than every stenographer in the country. None of you can disprove that. It’s true.
Tell your clients $1 per transcript. This is the situation we are all living together. Caveat emptor.
My Facebook page has become the steno channel. If it’s good for the working reporter, it’s on my page.
And though it may be difficult to read, I do try to keep it entertaining.
Christopher Day calls for Stenograph boycott, November 2021
For anyone that doubts calling out the bad customer service and horrible PR blunders is having an impact, you can stop doubting now. For the first time since March, Stenograph threw up a pro-stenographer image on its Instagram.
Stenograph Instagram, 11/17/21
Truth be told, I still view this sort of thing as corporate appeasement. They hope you will forget that they are screwing the students you mentor and continue to purchase their products and services. It’s a great sign that the Stenograph company wants to appease stenographers, because it means that we represent a large enough part of their customer base that pulling out wouldhurt. Withdrawing our support would matter. If more reporters heed my words and pull out fast and hard, we’ll be able to end this a lot sooner.
But seeing that image got me curious. I rolled through the Instagram to see the last time a comparable image was posted. There are some nice pictures advertising Q&A by Cyndi Lynch (who is awesome) and some marketing stuff, but nothing nice like this. While that’s a somewhat subjective measure, you can go through all the images yourself and see that the company hasn’t featured a person paired with a stenotype since about March.
The top left is November 2021, the bottom right is March 2021, Stenograph’s Instagram.
Follow me and our field gets results. Stenograph is eager to jump into a technology that will disproportionately hurt minority speakers. We are in a unique position to stop that.
It was reported to me that a call to Stenograph’s support yesterday took an entire 30 minutes of wait time. At the end of that 30 minutes, the call disconnected. The stenographer called back and was then forced to sit on the phone waiting about another 15 minutes. 45 minutes from call to resolution for someone that paid $139 for help with upgrading their software, on top of the support contract, which cost about $700 a year! I was just kidding about it being reported to me, I was physically present when it happened.
And this is not an isolated incident. It’s been an ongoing problem for months — Stenograph’s shoddy service, that is.
This is on top of reports that Luminex II is cracking in the same spot on the shell for multiple reporters. Maybe we should all start comparing notes and seeing if we are being sold defective products.
The problem is so bad that it simply cannot be hidden.
“I haven’t called today, but the last few weeks I had to call several times, and I have to wait a long time. Twice I just hung up and figured it out for myself.” -Stenograph Customer*“Happened to me last week. It was actually worse than the IRS, and that’s saying something.” – Stenograph Customer*“They’ve always been that way. Eclipse blows them away.” – Stenograph Customer*“Switch to Eclipse and it won’t be a problem lol” – Stenograph Customer*
It wasn’t all bad news though. They pull through for some of the people some of the time.
But they don’t fool all of the people all of the time. Stenograph is taking our money for support and then keeping us waiting on queues like we’re an inconvenience. They’re relying on our politeness and silence. Let me be the one to break the silence: This is wrong. We were propagandized for years to tell us that we needed support, and now the quality of that support is declining while Stenograph tries to build and sell its ASR business off our backs and with our money.
I suppose it ultimately doesn’t matter if Stenograph is sabotaging us. It leaves us to seek solutions to the problems we’re perceiving. Stenograph owners, the science shows ASR is a snake oil market. Make me a fair offer on the company, see if I can crowdfund the purchase. Much better than a boycott — we can get those trainers raking in the dough and make your employees happy too! Mr. Dutta can move on to some industry that doesn’t have a man with a blog. We all win. ChristopherDay227@gmail.com.
The alternative is to boycott Stenograph and buy it when it’s up for bankruptcy. It’s just business.
*There is no evidence that any of the comments were from Stenograph customers.
Some will have seen the scathing post I made on Friday about Stenograph’s survey. They wanted to know if court reporters cared about tall or short keys, and I pointed out that such a concern was a waste of time and effort. This is on the heels of news months ago from Stenograph customers that they were unable to log into their software. But the question remains, how do you get me, a stenographer that has exclusively used Stenograph products for 11 years, to write something like this?
Simple. Stenograph has been making moves to cuddle up with digital court reporting and ASR. We know this from who they’re hiring.
We know this from who they’re talking to. Stenograph cuddled up with anti-stenographer writer Victoria Hudgins after the customer base complained about the logo change. How do I know she’s anti-stenographer? I wrote her over a year ago to point out that Stenograph apparently gave Legal Tech a stock photo and that there were several inconsistencies with the companies, news reporting, and technologies at play. Was any of that addressed? No. So Hudgins writes as an “analyst” but does not actually appear to do any analyzing beyond the chosen narrative — very much like STTI. This is in stark contrast to other organizations like NCRA, NVRA, and Global Alliance, all of whom are far more fair and balanced in the way they present ASR and digital reporting than how stenography is treated by Hudgins, Cudahy, STTI, or even the AAERT.
We also know that Anir Dutta, President of Stenograph —
— is on the board of STTI.
[sic]
And we know that STTI is a digital reporting propaganda outfit. So it’s undeniable that Stenograph is diversifying. Under normal circumstances, we could maybe call that smart. But these are not normal circumstances. This is a world where we know ASR and digital reporting will hurt minority speakers. We know digital reporting outfits like VIQ Solutions are not turning a profit. We know that the shortage is being exaggerated and exacerbated by Veritext and US Legal. Stenograph is diversifying under the belief that there will be a drop in supply of stenographers and a rise in demand. The data we have today says the demand may not be rising as quickly as anticipated and the supply is not falling as quickly as anticipated. The Bureau of Labor Statistics data may also be wrong. In short, Stenograph is diversifying out of a market where its stenographer customers will likely reign supreme. We also know that they’re in such a rush to diversify that they branded over Phoenix theory with Phoenix ASR. Not too subtle about paving over us there.
I’m not the only one to feel that way. Massachusetts Court Reporters figured that all out too, and released an open letter earlier this week. The letter was reportedly also sent to Anir Dutta via email.
In full disclosure, I did help draft an initial copy of this letter, but what was ultimately released was way better than what I wrote. I also wrote a physical letter to Anir Dutta on November 2, which I will release someday in the future, assuming the company does not change direction. It is my sincere belief and hope that he is not against us. I think that he saw what happened to Kodak and he tried to adopt digital as a way of preventing Stenograph from sharing the same fate. A lot of the stuff we know about digital reporting companies today, we did not know when he started at Stenograph. But even if he has no animosity towards us, it will not stop him from making decisions that negatively impact our field, and so to the degree that Stenograph and Anir Dutta make decisions like that, the ball is in our court to stop them.
Now, stenographers, the important thing you need to keep your eye on is how the company responds to all of this. If the writing was on the wall and stenography was doomed™️, they wouldn’t care what you think. Put it this way: Have you ever asked yourself what a T-Rex would think of you? Probably not, because all the T-Rex’s that might have thought about you are dead. We know the writing is not on the wall and that our thoughts and opinions matter very much. How do we know? Stenograph commented on the situation.
And, of course, realizing that if we actually get Stenograph to change direction, the shortage fraud gets exposed, Jim Cudahy did his best to broadcast the message.
Just to be clear about why I’m not nice to Cudahy, he was the Executive Director of NCRA, urged the organization to commission the Ducker Report and learn about the stenographer shortage, and then used his previous title with NCRA to lend credibility to his false and misleading claims that the shortage is impossible to solve. People familiar with this situation basically point to him as the man that weaponized our shortage against us. The jump from NCRA to STTI was not the result of some profound change in technology, it was opportunism, plain and simple.
What I need court reporters to understand now is simple: You have all of the power in this situation. You tell the company as loudly as possible that you will not buy another product and that you will not recommend the company to a single student from now until the end of time unless they change direction, and they will change direction. If they do not change direction, it is clear just how much we meant to them, and it should make it even easier to walk away. If they change direction, I’ll be the first to say GO STENOGRAPH. Until then? I have to lean boycott. It’s our best play and the most direct way we have of influencing the company. Take all the anger we routinely experience via social media and channel it into something very simple and healthy for us all.
Now, inevitably, some will look at Stenograph’s response and want to side with the company. But here are some things to consider for each bullet.
1. Stenograph states it continues to invest heavily in Luminex II and CaseCATalyst. Maybe so. But let’s not shy away from talking about how quickly the company discontinues support for its products. When I was a young reporter in 2010, I was told by teachers that my first machine should be paper. I failed to follow their advice and I bought a Diamante. Not long after, Stenograph sold its paper business and systematically shut down support for anything “old.” My rebellious decision ended up being a smart one. The company does that so much now that we don’t even discuss it as a field. It’s kind of like the EA Games of Court Reporting.
2. Stenograph states it has doubled the number of engineers working on writing enhancements. This is impressive if the engineering team is fairly large, but for all we know they had one person working on it and doubled it to two.
3. Stenograph is releasing a new CaseCAT version in the future and is committed to continuous releases on an ongoing basis. There is no actual commitment here. If they change their mind, they can just say they were committed at the time.
4. Proof It, which is supposed to be ASR for stenographers, will allegedly improve efficiency 40%. There’s no actual reason to believe this claim since ASR from the largest ASR providers in the world is 25 to 80% accurate. 40% is pretty close to 50%. A real 50% efficiency gain would mean transcribing jobs in half the time. If Stenograph created something that could cut transcription time BASICALLY in half, they would be letting you know about that every second of every day until you bought in. Instead it is tucked away in this response.
5. Stenograph claims it continues to have dedicated stenographic teams, but again, this is actually not a commitment. A dedicated team can be dedicated to any number of things. They can be dedicated to digital reporting and stenographic reporting. In a field where two of the largest companies inflate numbers by a factor of six to fool stenographers, it’s not incredibly surprising Stenograph would play with some words in a perfectly legal puffery-like way. It would also be pretty dumb to maintain separate dedicated teams, since you’d be paying effectively double to staff the company.
6. Stenograph announced a partnership of Caseview Net with vTestify. It’s possible this supports my belief that Stenograph is not actively against us but rather being misled. vTestify was that silly company that I blasted for saying it could save attorneys $3,000 on a deposition. After that, they started working more on being a platform and less on being a service. So this, to me, says that Stenograph’s leadership just doesn’t know some things about our field. They wouldn’t tout a relationship with vTestify if they did.
7. Stenograph is committed to growing the profession. And they support this with their Project Steno donations. I hate to punch down on an effort that I commend, because I do commend Stenograph and every company that donates to pro steno initiatives. I actually wrote about Stenograph’s donation in a positive way when it happened. I like Project Steno and I often mention it right alongside A to Z and Open Steno. But at the end of the day we have to realize that Project Steno is a write off and there is a benefit to companies PR-wise and monetarily to donate to it. At this point, it comes off as a publicity stunt to get us quietly accepting the company’s lean away from us. Let’s face facts, NCRA dumped its corporate sponsorship program, US Legal and their pals realized they couldn’t get the NCRA to push the digital product for them, and ever since then there’s been this bizarre “separate but equal” stance where companies just happen to support Project Steno over NCRA or NCRF. Considering that NCRA is basically THE trade association for stenographers, it’s easy to see that the goal is to undermine the stranglehold stenographers have on the market. That’s basically how I regard Project Steno at this point. A convenient place for all the entities not supporting NCRA to point and say “we care about steno too!” It’s called hedging.
8. Stenograph donates hours of training. Most vendors donate when asked. It’s kind of a chicken and egg, cost of doing business thing. You have a society of people, court reporters and stenographers. You have organizations that try to bring these people together, like NCRA. Playing ball with the organization that gives you access to your customers is called par for the course.
9. Stenograph uses a dedicated technical support team. Again, the word dedicated doesn’t even mean anything to me. It wouldn’t surprise me if the “dedicated” tech support is outsourced in whole or in part, just like their stock photo office picture.
I asked some of my audience to give me their comments on Stenograph’s bullets. This is some of what your fellow reporters say:
Respondent A: “My thoughts on it – One of the best things my dad ever told me was “You should always listen to what people have to say, but it’s more important to watch what they do.”
This is a typical PR response, and it sounds nice. But what I see Stenograph doing is channeling their resources to directly compete with their primary customers. What I see is Stenograph entering into increased alliances with STTI (a digital front, despite what they say), and AAERT. What I saw from Stenograph at the NCRA convention was a booth and their separate training offering (I think people had to pay for that in addition to the convention, but I’m unsure on that. If so, then they didn’t “donate” the training.) I saw a decreased level of event sponsorship. When I open the JCR, I no longer see any ads from Stenograph. These actions certainly indicate to me that while of course they would like to keep their steno customers, their focus is now on their digital product.
And I’d like to know if by integrating their realtime platform (CaseView) with VTestify, they plan to mine those transcripts to improve the AI for their digital program.”
Respondent B: “Thanks for sharing. The language in that post and PDF is basic and appears to have been written by a sales executive. Not a whole lot of depth there.
Two things:
Are they going to begin manufacturing and/or selling digital recording equipment?
Their last bullet point appears to be more about shortening their customer service employees’ time on service calls. The language is unclear about their policy or commitment to meeting their stenographic customers’ needs.”
Again, one thing is for sure. If the writing was on the wall, Stenograph wouldn’t care what you have to say. It has tipped its hand and admitted it cares very much. Use your collective power as consumers and walk away until the company is behaving in a manner that is actually accountable to you and not lip service. Let them know that’s what’s happening. Let them know it’s because of me if you want to. They’re using their position as a tech company to make you feel unqualified to judge their product. Meanwhile, when you ask someone like Stanley Sakai, someone that knows computer programming and steno, he can tell you why we use stenotypes. I can too. Why can’t Stenograph? The company has a monetary incentive not to. Take that away and you have a company with no choice but to support us or fold. If the company was on solid ground, we wouldn’t be able to cut through its arguments like Darth Vader cutting through rebel troops at the end of Rogue One. The company’s condition today is not our fault and we shouldn’t feel guilty about using it to our advantage. Certainly no one in this industry has felt guilty about using us.