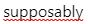Bottom line is a dude allegedly goes to get some boneless wings, the boneless wings have a bone inside, and he gets injured. Like I said the other day, I’m not a lawyer, but this is a very straightforward negligence case, issue to be put to a jury.
The trial court dismissed his case on summary judgment and the appellate court upheld the ruling.
Generally, in summary judgment, the court is supposed to look at the evidence in the light most favorable to the non-moving party and decide “could a jury find in favor of this person?”
The trial court decided that boneless doesn’t mean boneless, but describes the manner in which the meal is cooked.
Yeah. Seriously.
So could a jury find this corporation at fault because it had bones in its boneless wings and this guy got injured?
The Ohio Supreme Court says no.
I say fuck the Ohio Supreme Court. These shysters hide behind legalism and say “we shouldn’t be influenced by the media.” Um, here’s some more media from someone who’s been around enough lawyers to know this is a garbage ruling.
Ohio Supreme Court bows down to corporate power and decides boneless doesn’t mean boneless
Maybe when you’re deciding cases shouldn’t even go to trial because they might not go well for corporations you’re bought and paid for and need to be ripped off the bench by the masses. That’s what would happen in a civilized country, but thank God for all of you, we live in America, a nation of laws.
Of course, this is as always, my stupid dirtbag left performative style. I would never advocate for actual violence against judges that are ready to sell our country out to corporate interests because “muh economy.” But I will not be silent about it.
I would brand them treacherous snakes. Maybe the legislature needs to write into law that the court can’t make up definitions of words and that they’re subject to immediate removal when they do? I don’t know. But you can’t leave this alone. This is the denial of trial by jury by, again, treacherous snakes who deserve no respect and bring great disrespect to the rule of law through their hideous actions.
The dude’s case is dead in the water. Others should not suffer the same fate.
As the lawyer in the video says, nobody is saying the guy deserves money. We merely suggest that there’s enough evidence at a glance to send the matter to a jury.
This country’s infected man. I’m waiting for people to rise up.
Corporatists beware, people like me are starting to get into legislatures. We’re in all the branches of government in fact. And before long you’ll be purged from government one way or another. Votes, rulings, laws — we will fight and we will win because America will be stronger for it.
On Thursday the Onondaga Criminal Court arraignments had a surprise visit from the embattled z-list court reporting personality, X, formerly known as George Santos. Santos, having been charged with being too compliant with police officers, was discovered to be a stenographer just shortly into the proceeding.
Stenonymous publishes “real” court transcript for creative writing exercise.
After the reveal, Mr. Santos was asked by the Court to relieve the official court reporter taking the proceedings. Mr. Santos allegedly turned to her, smiled, and said, “don’t worry, I got this. I’m the NCRA Fastest Fingers Award Winner of 2023. Elon Musk is going to buy you a horse for your trouble.”
Once Santos was behind the keys of the stenotype, the rest of it went well for him. In the transcript obtained by Court Tee Vee, an unprecedented situation unfolded.
THE COURT: Well, Mr. Santos, it seems there’s been a mistake. Your lawyer, Mr. Richards, has pointed out that the accusatory instrument has a fatal defect. The case is dismissed and sealed.
THE PROSECUTOR: Oh, Mr. Santos, we are so, so sorry for our malicious prosecution. Please don’t use the transcript of this proceeding to sue us.
MR. RICHARDS: My client is a benevolent and understanding person. In addition to being the first man to the moon and the only person to single handedly save an entire school bus of children with his left pinky, he donated enough to charity to end world hunger and eliminated unemployment worldwide. There’s no reason for him to sue you, and your apology is humbly accepted.
THE COURT: By the way, Mr. Santos, thank you for ending the court reporter shortage fraud by creating a controversy so obnoxious that there isn’t a single person that hasn’t heard of stenography. That was a bold move, and it really paid off for your profession, they should be proud.
THE DEFENDANT: Your Honor, it was no trouble. The court reporters living here and working every day to make this county shine, they’re the real heroes.
(Whereupon, court officers and court clerks all broke into tears as the sun shone through an open window and a beam of light cast a spotlight on X, formerly known as George Santos. As he exited the courtroom, a flock of doves carrying the mice from Cinderella fluttered through the window and dropped their furry friends, and everyone left the courtroom while singing We All Lift Together from the worldwide critically acclaimed MMORPG Warframe. Yes, including the mice and doves.)
Critics question the parenthetical at the end. Court officers, known for their professionalism, helpfulness, and dedication to the safety of courthouses, and clerks, also known for their professionalism and dedication to the just and fair operation of courthouses, simply don’t do that kind of thing. A source speaking on the condition of anonymity stated that in reality, the relieved stenographer was actually 1,567% more qualified than Santos, so we’re not really sure what occurred that day.
Breaking news. Check back for more updates.
*None of this is real. It’s part of Stenonymous Whatever I Want Weekends, a thing I just made up for when I want to do something different like this parody of so many flavors. According to a source that wishes to remain anonymous, in the incident this was based on, the erroneously-charged case was dismissed and sealed 14 days after arraignment. The source believes that a small percentage of our field does not understand the gravity of our work and how it can impact people’s lives, and that by making this excerpt and attached writing exercise public, we can all be reminded that anyone can be charged with anything, and that treating all lawyers, litigants, and the public equally is imperative. “It could be any of us one day,” he said.
Thanks again, Anonymous. I share these beliefs, but even if I didn’t, I’d probably have published anyway for the literary and conceptual value.
From Anonymous and myself, thank you for making this profession shine every day with your hard work and dedication.
*The initial version of this post was written in a vulgar, ranting, raving, and confusing manner due to a medical episode I was having. Sorry for how that was written. I have scrapped it. It held no creative or intellectual value that cannot be reproduced at a later date. Many of the people I named and cursed at are actually good people that I admire.
See the new version below:
This time, with love.
The “conspiracy” is simple. It is very similar to what Purdue Pharma did to healthcare. Lies and misdirection, as well as possible government corruption. I should note that in our case, because the government has not yet investigated to my knowledge, it is hard to tell if we’re seeing tacit parallelism or a fully-planned plot. That said, numbers do not lie, and there are problems with the numbers.
Veritext, US Legal, STTI, and others publish misleading and demonstrably false info. There is likely a baseline assumption that it won’t matter in 10 or 20 years because AI will “take over.”
Our associations, either by design or habit, just keep staying the course. Old tricks don’t work in a new and modern world. I start to change minds with a $10,000 budget and become suspicious of the association management industry. Dave Wenhold, whose intelligence and charisma I openly admire, becomes suspicious to me. This is about where I start to deteriorate. How do I use my media to bring people to associations that shut down new ideas without debate; as NCRA did for Amendment 5 this year? How do I support associations that give responses so boneheaded a six year old could do better? Even my beloved NYSCRA seems intent on crushing new ideas quietly and behind closed doors.
NYSCRA also seems oddly inert whenever I suggest anything that would strengthen the association.
Then, like with Purdue, there is potential government corruption. There is a concept called the revolving door, where someone on behalf of the company catches the ear of a government official and the government official just so happens to do what the company wants. Then the government official retires to a nice new job with the company. So far I’m told California Court Reporter Licensing Board officials have actually done this — which is incredibly suspicious. California may well be the state with the strictest regulations for court reporting. It refuses to regulate digital court reporting. Consumers should probably demand the complete dissolution of the board. It would be like heavily regulating snack foods but refusing to regulate pretzels.
Let’s not forget Arizona, where my public comment was completely ignored by Director Byers, even though I sent him an e-mail well before my personal issues began. Very convenient for AAERT and anyone who thinks courtrooms should be investing in recording equipment.
There are also issues here in New York. It is apparent that members of the public are being told no spots are open and the government is sitting on provisional applications.
I cannot say for sure what we are seeing. I do see a pattern of passive aggressiveness toward court reporters from corporations, associations, and government — a passive aggressiveness that peculiarly fades any time someone questions it.
The antitrust conspiracy may not be an actual conspiracy. But if I was designing a plot to exaggerate and exacerbate the stenographer shortage, it would look exactly like what we are experiencing today.
A source that shall remain anonymous passed me information that NYPTI prosecutors were being given education about stenography and court reporting that doesn’t match up with reality. During the presentation, stenography was made to look as old and outdated as possible when in actuality it is top-of-the-line tech in speech-to-text transcription. This supports my belief that the stenographer shortage is being intentionally exaggerated and exacerbated.
Stenographers are no strangers to social media. We’ve had students like Isabelle Lumsden get thousands of eyes on our stenotypes. We have amazing content from accounts like Stenoholics. More recently, I got to see a video from the TikTok letsgetfries. The video starts with our hero mentioning that she’s been on jury duty for two weeks. The most important thing she’s learned? Stenographers have the wildest energy of anyone she has ever met in her life! Don’t fuck with them. Maybe she’d make a good court reporter, she got our hand and eye thing down already!
This is exactly how I look at work every day for the last 11 years and she nails it.
I bring this up for the entertainment value, but also as a reminder that strategically social media is our battleground. There are companies out there right now, like US Legal, that are claiming the stenographer shortage cannot be solved by training more stenographers. It’s a blatant lie dressed up like industry news to fool industry insiders and outsiders. Meanwhile, we know from the Open Steno 2021 Survey that about two thirds of people coming into contact with steno, at least in that community, are coming into contact with it thanks to the Internet. So we’ve got to out-presence them, recruit people, and steer our students clear of dishonest companies.
OH NO. EQUATIONS. RUN.
And make no mistake that I am calling US Legal dishonest. In their article they note 1,120 retirees a year and 200 new reporters. An annual shrinkage of 920 reporters, giving the impression that this is an annual gap that never ends and only gets larger. But that’s not how these numbers work. First of all, they’re extrapolated from the Ducker Report, which was a forecast based off 120 interviews and some proprietary data analysis, not a future-telling machine. As more and more reporters retire out, the retirees would decrease each year. Anybody with a second-grade math level can figure out their math is wrong because a shrinkage of 920 annually means there would be zero reporters in 30ish years. That’s not actually possible if you’re getting 200 new reporters a year. The equivalent would be me going on JD Supra and saying the CEO of US Legal gets two brain cells a year and loses ten, therefore his company will probably be bankrupt in ten years. Doesn’t matter if it’s true, it just sounds good. I don’t begrudge people for where they work, but as a company, no matter how great any individual employee might be, they’ve got to be among the most dishonest, toxic, harmful companies in our industry. You know that scene in Star Wars where Luke tells Kylo “amazing, every word of what you just said was wrong”? That’s how I feel. Reporters get some cognitive dissonance here because US Legal does have nice people working for them, but that doesn’t change how I feel about the entity itself. It’s like Theranos. I’m sure nice people worked there, but the entire operation was a big joke that should never have happened.
Letsgetfries, I don’t know if you’ll ever happen across this, but let’s just say we’re so used to being treated like potted plants that whenever anybody says anything nice about us, we boost them big time. From getting Stanley Sakai’s article featured on Medium last year or sharing John Belcher’s deposition strategies. You’re no different. As of late last week we had shared you over a thousand times! Hope you had a great experience with jury duty! If you know anybody who’d like to join our field, please let them know about NCRA A to Z, Project Steno, or Open Steno. For the record, our crazy energy is mostly thanks to everyone saying they can replace us and failing for the last half decade. We’re working it out. Thanks again!
Spreading through social media is a clip from John Belcher. He talks about how he got his dream job as a prosecutor, which allowed him to be in court almost every day and work with court reporters and other court staff. He talks about all the things that court reporters hope attorneys talk about. Some key takeaways?
Don’t do something you wouldn’t do in front of the judge. They read the transcripts.
Don’t step on the witness. Count to four before starting the next question or answer.
Speak a little slower. He suggests 70% speed.
Don’t disrespect opposing counsel, the witness, the court reporter, or other attendees.
Be careful about side discussions that take away or distract from the proceeding.
Adding fillers at the beginning of questions like “okay” or “perfect” may create bad habits for trial questioning.
Preparation is key. Expecting the court reporter to put up your exhibits for you may burn valuable time.
Don’t take it from me, check out his video on LinkedIn today! You can also see his YouTube here.
A close friend sent me a Bill Maher clip from a while back. Obviously, Maher has his political leanings, but after he gets done with flaunting those, he makes a decent point. He describes the over-engineering of society and gives some pretty striking examples. His preferred vape’s newest model has no mouthpiece despite being something you put in your mouth. Car handles are replaced with buttons in some cars despite no efficiency gains. He describes a situation where his rental car asked him if he’d like to open the trunk while going 60 miles an hour. The point is clear, change for the sake of change is not always worthwhile or efficient. Indeed, change for the sake of change can be very dangerous.
This is connected to the exaggerated claims of salespeople that I’ve written about extensively, especially as it relates to voice recognition. I described it several posts ago as the claim game. Anybody can say anything. Anybody can make their business seem like the new, hot thing. Take this blog post by Kaplan Leaman & Wolfe from about a year ago. It reads nicely, and it sounds innovative. It mentions a flat-rate fee, affordable per-page price structure, a design to significantly reduce legal expenses. At the point in 2020 the post was written, everybody was doing remote stuff. Pretty much everybody’s got a per-page price structure. Anybody can claim their service is affordable or reduces expenses. It’s called puffery and it’s an ordinary part of business.
Where it gets messy, and where I’ve tried to educate reporters, is some advertisements are easier to spot than others. If Burger King says they’ve got the best burger, most everyone knows that’s puffery and sales. Things get harder with technology. How do you prove or disprove whether someone has made a technological breakthrough without a comprehensive understanding of the science and concepts at work? Not all reporters understand the concept of machine learning. Even those of us that have researched quite a lot can’t possibly know everything there is to know. This leaves a gap for tech sellers to come in and try to fool consumers into buying services that may not suit their needs using the hype train.
Told you I write a lot about this. I read a decent amount too.
This also leaves reporters playing a catch-up game of learning about these systems so they can help their clients navigate claims and discern fact from fiction. For example, the truism that technology is improving every day. We look around ourselves and marvel at this magical modern world. But I’ve taken the pretty hard stance that certain technologies, namely voice recognition and associated technologies, are not improving every day. Give it speech it’s used to and it’ll do fine. Give it speech that’s just a little off from what it’s trained for and it’ll turn “would you raise your right hand” into “it’s rage right hand.”
Yes, it’s rage’s right hand.
But surely reinventing the wheel and all these claims of being BETTER aren’t BAD for business, right? If puffery is normal then a little bit of stretching the truth won’t hurt anybody! But we already see that’s not the case. Take Maher’s example. One little glitch on the highway and you could have dead motorists. Take the fact that 25 percent of court reporting companies may be unprofitable; court reporting has been around a long time, it’s likely the losers are the ones trying to switch it up too much too fast. Take vTestify’s massive switch from boasting about providing inexpensive court reporting services to providing an online platform for the legal industry. Take Verbit’s claims in its series A funding of 99 percent accuracy and its subsequent announcement that it will use human transcribers after all, and the very real possibility that it is, despite all its funding, not profitable.
Exaggerated claims serve only as a cliff from which these companies have a chance to walk off of or step back from. The competition is going to wise up. The consumers are going to wise up. I can only hope that a lot of these tech companies realize this, wise up, and start putting their resources behind actually improving our technology. It’s a lot easier to compete in a field with maybe seven players like Stenograph or Advantage than it is to beat out thousands upon thousands of independent contractors and hundreds of reporting firms, many with their own clients and connections. It’s frighteningly easy to see there’s a more lucrative path than over-engineering what stenographic court reporters have made simple, and I can only hope that business owners realize this before walking investors’ money off that cliff.
This month I had a chance to sit down with Marc Russo of MGR Reporting. Marc’s a working reporter and business owner. We got to hit a lot of topics in this video, including Marc’s history in the field, how reporter skill relates to reporter treatment, and how scheduling ahead can help reporting firms fill their clients’ needs.
Using Marc’s words, it’s about treating reporters like people instead of numbers.
Very often on stenographer social media, we get questions about whether something should be reflected as said, sic’d, or “corrected.” There has been plenty of discussion over the years on whether to correct lawyers’ or witnesses’ speaking in transcription. There are a lot of ways to take this conversation, and in the spirit of keeping this fun, I’ll hit the highlights.
Necessary in this discussion is: “What is my transcript?” The bulk of freelance work goes to deposition reporting. When a case is filed and initial motions to dismiss are decided, if the case is not dismissed, it moves to discovery. Discovery is where the parties exchange information that they have so that when it is time for trial, there are few or no “surprise” pieces of evidence. At the conclusion of discovery, the parties can ask the court to decide the case as a matter of law if there are no factual questions in dispute. If the case cannot be resolved as a matter of law, it goes on to trial. An integral part of the discovery phase is deposition testimony. Parties have an opportunity to question the other side’s witnesses under oath. Witness testimony is evidence, and the evidence unveiled during the discovery phase is ultimately what helps parties settle cases, courts decide whether a matter can be decided as a matter of law, impeach witnesses at trial, and appellate courts review the decisions of the trial court. In America, the testimony of one witness can convict beyond a reasonable doubt. Your transcript is the verbatim record of what occurred during the testimony, and again, that testimony is powerful evidence.
Unsurprisingly, there are many different takes on what “verbatim” means. We can all read the dictionary definition: “in exactly the same words that were used originally.” But court reporting and transcription are service industries, and there have been many times where court reporters are pressured by a client or company to change that verbatim record in some small way. In my view, that pressure gave life to a lot of court reporter conventions that are daunting for students, new reporters, and even veteran reporters to master. For example, as a young reporter, I was told to take out false starts, never ever report “um,” and to even physically remove strikes and withdrawns from deposition transcripts. Now, wherever you are, the laws in your jurisdiction supersede my advice or opinion, but I am going to share the way I look at each in the hopes that this can be shared with others who struggle with these. For sure, anything I write can and will be debated, but debate can only improve our field.
Removing False Starts
This was drilled into me by agencies as a young reporter. “Always remove false starts.” It’s still being pushed on young reporters today, to the point where some may not even be taking them down. Frankly, I see this as bad advice. The essential factors for a reporter to consider in the way something is transcribed are context and readability. Does my transcription of the verbatim notes change the context of this testimony? Does my transcription degrade the readability of this testimony? In my view, removing most false starts will not actually change context, and they will improve readability. As an example:
“Q. Are you — did you go to the store?”
“A. Yes.”
It would be difficult to argue that removing the words “are you” and simply changing the question to “Did you go to the store?” hurts the context. Nothing has changed. And so to the extent removing false starts is looked at favorably in our field, I get it. But what about when it would change context?
“Q. Are you — I mean, did you go — did you go to the — sorry. Did you, if you remember, go to the store?”
“A. I’m sorry. I don’t understand your question.”
What happens in a world where a young reporter, told that they must remove false starts, removes all that and changes it to “Did you, if you remember, go to the store?” The context is unequivocally changed. Verbatim, it’s very clear that the question was not clear. There was a lot of extra “stuff” in there. If such a question is cleaned up, it makes the witness look like they’re not paying attention or unintelligent. Removing false starts can hurt the context and stop legal professionals from doing their job. Imagine that the deposition is taken by a young associate and the trial lawyer is a seasoned vet who did not sit on the deposition. Reading a “cleaned up” version, the trial lawyer might believe the witness is a bumbling mess. When that witness gets on the stand and is given clear questions, it’s going to be a surprise for that trial lawyer. So even where law may allow the removal of false starts, it’s a decision the court reporting practitioner should make using their own sound judgment, and not on the whims of an agency or client. You may also want to see NCRA Advisory Opinion 4 to the extent it touches on this topic.
Never Ever Report Um
Again, I see the reporting of “um” as a matter of context and readability. Let’s say that you’re taking a motion argument, and it looks something like:
“MS. ATTORNEY: Um, um, um, um, um, um, um, um, um — your Honor, based on the hearing that we just had, there is no set of facts under which the people may prevail. I therefore ask you to dismiss this case in the interest of justice.”
Does it really change anything if you don’t report the ums in that specific instance? Nope. And this isn’t a hypothetical. I recall a situation just like this, where the attorney had, without question, made the point they were trying to make, and then became very flustered asking the court to make a decision. But what if the situation was a trial situation?
“Q. Did you see Mr. Vanhorten shoot Mr. Gorfasi?”
“A. Um, well — um, yes.”
If you transcribe that sentence as “well, yes” the context is destroyed. The witness seems crystal clear on what they saw. Those ums have a kiloton of context that transform what is being said. I’m not here to say anyone who omits an um is a bad reporter, but think twice before subscribing blindly to the “truism” that we do not report ums.
Physically Remove Strike That or Withdrawn
Often, strike that is seen as a false start. Just imagine the typical scenario:
“Q. Were you — strike that. Were you ever an employee of ABC Corporation?”
Again, the rule of context comes into play. In the above scenario, I can’t say I see a big problem with the omission of the false start strike that. But as a mentor to many over the years, I’ve come across the following scenario:
“Q. Were you ever an employee of ABC Corporation?”
“A. Well, I wasn’t an employee at the time.”
“MR. GUY: Move to strike.”
What have mentees come back and said? “Chris, my agency says remove strikes. Do I remove that whole thing?” Working reporters have had to counsel many a new reporter. “No. We cannot remove portions. That motion to strike is the attorney preserving their motion on the record, which will be later reviewed by a court.”
Ultimately, with these three categories, leaving things in as they are said is often the way to go. A court can always seal, strike, or disregard something that shouldn’t be in the transcript. On the other hand, a reporter that does not put something in the transcript can be questioned about why it was removed, or even have their neutrality called into question.
Mispronunciations
Now that we’ve explored some of the common things that impact context, let’s explore some more “what ifs.” Since I was a newbie, the discussion has come up, “Someone said a word incorrectly. Should I sic this?” This comes from a very literal way of thinking sometimes cleverly but pejoratively termed in our field as “the literati.” The pressure is turned up to make something “perfectly verbatim” when there is a video, which brings up the question “are we not being verbatim when the video camera’s not on?” There are two major schools of thought, literal verbatim and readability, and within those schools of thought, you have many different situations and many different gradients. I could not possibly address each one, but let’s hit some common examples.
“Let me ax you a question.” It’s obvious to anyone that the speaker means to say ask. Many speakers do not enunciate clearly. It does not change the context to transcribe “ask,” and it greatly improves the readability, so for such moments where the context is not endangered and the word is obvious, there’s no harm in having the correct word rather than some kind of phonetic spelling. I would say the same for names. Let’s say someone’s name is Dr. Giglio. One person says “Jig-lee-oh” and the other says “Gig-lee-oh.” Again, if it’s clear that this is the same person, and the context is not endangered, transcribing the correct name is the way to go. If it’s not clear, then it’s time to speak up and get some clarification on the spelling! This is not to say you can never write a name phonetically, but try to make these spellings consistent throughout the transcript to the extent people are saying the same word, even if they say it a little differently.
“It’s supposably true.” In addition to not changing context by being too verbatim, we have to be mindful that sometimes people use words that sound like other words. If someone says a “wrong” word or a word we are not accustomed to hearing, we must resist the urge to correct, because that actually can alter context. We must also take the time to research things we are not a hundred percent sure on. In my book, supposably was not a word. The WordPress spellchecker says it’s not a word. I came to learn, a decade into my career, that supposably means “as may be conceived or imagined.” Supposedly is more of a synonym for allegedly. Was this true 10 years ago? I have no idea. As court reporters, we face the harsh reality of language drift. Words fall in and out of use. People do not speak as we were taught. So while you might correct something like axing a question, you have to think twice before you correct something that’s “supposably wrong.” If you have three minutes, check out my favorite video illustrating language drift. You can go back about 700 years before English starts sounding like gibberish and giraffes were camelopards. Through a mix of self-initiated research and our continuing education culture, we keep ourselves ahead of the average transcriber.
Whether there is video or not, you want a clear and logical reason why you have transcribed something the way you transcribed it. In my view, the strongest reason for a transcription choice is “transcribing it any other way would change the context or was not verbatim.” Reporter convention and training take a backseat to that.
What devilry is this?
Dialects
Court reporters are masters of English dialects even when we have no training. There is a study out there that pretty much shows we are twice as accurate as laypeople when transcribing the AAVE dialect. The thing that makes us, as humans, so much better than computers at transcribing speech that has a dialect or an accent is our ability to understand context. For example, in the Northern Cities Vowel Shift dialect, someone might say something that sounds like “she went down the black.” Dependent upon the context, we know that that sentence can be “she went down the block.” In brief, our ability to look at the totality of a statement is important. What a reporter may hear is “down the black.” But what must be transcribed, in the interest of both context and readability, is “down the block,” unless there’s some context that tells us “black” is actually correct.
This is also where our ability to speak up for the record comes into play, because if a reporter is unsure, they can seek clarification. For purposes of our work, dialects and accents are very much like garden-path sentences where a sentence goes in a different direction from what you were anticipating; we can discern what’s said from the context. Though accents are a different animal from dialects, the same rules apply. Early in my career, I had a gentleman say something that sounded like “I got up and leave her.” Through context I knew the statement was “I gotta pull a lever.” He was explaining how to open bus doors! Another man talked about the “zeh bruh lies or stripes” on the road, which could only be “zebra lines or stripes.” We’re not here to pick apart how something was said, we’re here to take down what was said.
Latin
“Vice-a versa” versus “vice versa.” “Neezy preezy” versus “nisi prius.” “Nun pro tunc” versus “nunc pro tunc.” “In forma papyrus” versus “in forma pauperis.” Because of Latin’s considerable history and various modern regional pronunciation schemes, this is another thing that gets confusing fast. My advice? Treat it like mispronunciations. Treat it like dialects. Treat it like all these other examples and look at the context. If someone says, objectively, the wrong phrase, then don’t change it for them, but if you know exactly what they said, don’t transcribe it phonetically for the sake of “verbatim.” Take a look.
“MR. GUY: Quid pro quo is the Latin phrase for ‘from possibility to actuality.'”
So we head over to Google, and we can see clearly that “a posse ad esse” is the Latin phrase for that. Quid pro quo means “something for something.” No correction is necessary here. We knew what was meant, but the wrong thing was said. Verbatim is our friend. But what if it’s just a butchered pronunciation?
“MR. GUY: vee-low-shee-yee-yus quam asparagi coke-a-tor is the Latin phrase for ‘faster that asparagus can be cooked.'”
MR. GUY: velocius quam asparagi coquantur is the Latin phrase for ‘faster than asparagus can be cooked.'”
If you’re following along, you can probably tell that I think the second one is the obvious choice. No matter how butchered that pronunciation might be, if it’s clear, transcribing the wrong word or a series of phonetic jabs is what a computer would do. You’re better than that, use it to your advantage. And do not be too hard on yourself for making a mistake. I have had colleagues that were told the incorrect spelling of Latin phrases by people far more educated than many of us are. Whatever the issue, learn from various mistakes and situations, try not to become so rigid with regard to language that it endangers context, and continue to grow.
But I Was Taught This Way
Whenever stuff like this comes up, inevitably you’ll get responses like “but I was taught this way,” or “I’ve been doing it my way for 30 years.” Nobody can really fight with that. We have to respect one another and those various perspectives, backgrounds, and experiences. But I’ve come to look at it from a liability and reputation perspective for the freelance court reporter. If someone questioned you on a transcript, how would you respond? “My agency told me to” is a very unsafe response, because the agency can just say they didn’t, and if you’re an independent contractor, they’re not supposed to have direction and control over you. So take a look at the practice, and imagine being questioned on it. “That’s what you said” is a much stronger response than “everybody does it this way.”
We have to deal with the fact that, while we may live in a world of “truisms,” like “clients expect us to clean up the record,” these things are not universal, and in fact, as a young reporter, I had a lawyer tell me “you can’t change [false starts], it’s part of the record!” Imagine being about 20, and repeatedly told that “everyone cleans it up,” “this is normal,” “this is expected,” “you’re a bad reporter if you don’t fix it,” and then being slammed with “you can’t take that out.” It’s not surprising to me that there are reporters of all ages and experience levels that struggle with this. I’m really hoping this helps the strugglers: I was you. You’re not going to have an immediate answer for every situation, but having an objective or neutral method for how you make these decisions is imperative. If problems arise, and they occasionally do, you’re going to be defending your work. Remember, this is all about having an accurate record for review by the parties, trial courts, and appellate courts. Our expertise is what stops errors like “lawyer dog” from making it into the record and ruining people’s lives. If your work hasn’t changed the context of a statement and the transcript is readable, you’re off to a great start.
Allie Hall is a reporter and educator who has made amazing strides in getting schools to pick up court reporting programs and getting students filling those programs. Some months ago, a group of working reporters came together under Allie’s guidance and leadership, and with additional help from co-admin Traci Mertens, the group has managed to donate thousands to new reporters and students in need.
If you are a working reporter or CART writer looking to give back, please reach out about joining the group. There is a fundraiser currently ongoing, and working reporters may donate ten to twenty dollars to help meet students’ needs.
Working reporters may donate via:
Venmo: Allison-Hall-89
PayPal: allie441@gmail.com
Google Pay: allie441@gmail.com
There is truly no contribution too small. If you’ve got an extra ten dollars to put down on a student, consider sending it along to Allie today! I am a contributing member of the group, and I have rarely ever seen such energy and accountability in a grassroots fundraiser. This is something special, it’s something I really support, and I know the money is going to making the road that young professionals have to travel just a little bit less bumpy. Most of us can look back at our student years and say “I wish I had…” Now we get to be a part of making sure the students of tomorrow have!